by Rajat Jindal | May 21, 2026 | AWS
The Richest Data Source You Are Not Feeding to AI
Every enterprise AI initiative starts with the same discovery: “What data do we have that could power this?” The team surveys CRM records, support tickets, product documentation, customer emails. They build Knowledge Bases, generate embeddings, and deploy copilots.
But there is one system — the one that contains the most valuable structured business data in the organisation — that is almost never connected to AI in the first wave. It is your SAP ERP.
SAP holds the ground truth of your business: every purchase order, every invoice, every goods receipt, every vendor payment, every production order, every financial posting. It is the system of record for procurement, finance, supply chain, manufacturing, and HR. It contains ten years of transactional history that no other system in your enterprise possesses.
And yet, in my presales engagements across dozens of enterprise AI initiatives, SAP data is consistently the last to be connected — if it is connected at all. The reasons are always the same: “SAP is too complex,” “the ERP team will never approve it,” “we don’t know how to extract data from SAP safely.”
These objections are real but solvable. And the enterprises that solve them first will have an AI advantage that no competitor can replicate — because no competitor has their SAP transaction history.
This post is about why SAP data is the highest-value AI data source in the enterprise, how to connect it to AWS AI services without disrupting your ERP, and the business outcomes that become possible when your AI can finally answer questions that only SAP knows the answer to.
Why SAP Data Is Different: The Unique AI Value Proposition
Other Systems Tell You What People Said. SAP Tells You What Actually Happened.
CRM data tells you what a salesperson recorded about a customer conversation. Support tickets tell you what a customer described as their problem. Emails tell you what people promised each other.
SAP tells you what actually happened: the purchase order that was raised, the goods that were received, the invoice that was matched, the payment that cleared. It is the financial and operational ground truth — not a record of intentions, but a record of actions.
For AI, this distinction is transformative. An AI grounded in SAP data does not hallucinate about business performance — it reports what actually occurred, with document numbers, timestamps, and financial amounts that tie back to auditable transactions.
The Data Moat
Every enterprise has access to the same foundation models. Every enterprise can build a chatbot. The differentiator is not the AI — it is the data the AI has access to.
SAP data is the ultimate proprietary data moat:
- Your vendor payment history is uniquely yours
- Your procurement patterns are competitively sensitive
- Your production efficiency data reflects your specific operations
- Your financial transaction history tells the real story of your business
An AI connected to this data can answer questions that no public AI tool, no competitor, and no generic analytics platform can answer. That is the competitive advantage — and it compounds with every month of transaction history.
The Three Barriers (and How AWS Solves Each One)
The reality: SAP’s data model is complex — normalised across hundreds of tables with cryptic naming conventions (VBAK, EKPO, BSEG, MSEG). Extracting meaningful data historically required deep ABAP expertise and months of development.
The AWS solution: Amazon AppFlow provides native SAP connectors that extract data from SAP without ABAP development, without impacting ERP performance, and without exposing the underlying table complexity to downstream systems.
{
"flowName": "sap-procurement-to-s3",
"description": "Extract procurement data from SAP for AI consumption",
"sourceFlowConfig": {
"connectorType": "SAPOData",
"connectorProfileName": "sap-s4hana-production",
"sourceConnectorProperties": {
"SAPOData": {
"objectPath": "/sap/opu/odata/sap/API_PURCHASEORDER_PROCESS_SRV/A_PurchaseOrder",
"paginationConfig": {
"maxPageSize": 5000
}
}
}
},
"destinationFlowConfig": [
{
"connectorType": "S3",
"destinationConnectorProperties": {
"S3": {
"bucketName": "enterprise-data-lake",
"bucketPrefix": "sap/procurement/purchase-orders/",
"s3OutputFormatConfig": {
"fileType": "PARQUET",
"prefixConfig": {
"prefixType": "PATH_AND_FILENAME",
"prefixFormat": "YEAR/MONTH/DAY"
}
}
}
}
}
],
"triggerConfig": {
"triggerType": "Scheduled",
"triggerProperties": {
"scheduleExpression": "rate(1day)",
"dataPullMode": "Incremental",
"scheduleStartTime": "2026-05-01T02:00:00Z"
}
}
}
The key architectural decision: incremental extraction on a schedule rather than bulk extraction. AppFlow pulls only changed records since the last run, keeping data fresh without overloading the SAP system. The ERP team’s concern — “extraction will degrade our production system” — is addressed by design.
Barrier 2: “The ERP Team Will Never Approve Access”
The reality: SAP teams are protective of their system — and rightfully so. ERP downtime is a business-stopping event. Any integration that risks performance or data integrity will be blocked.
The AWS solution: The extraction architecture operates through SAP’s OData APIs — the same API layer SAP itself provides for external integrations. It does not require direct database access, ABAP development, or changes to the SAP system. The SAP team approves an API user with read-only access to specific OData services — nothing more.
The governance conversation that works with ERP teams:
- Read-only access (no write-back to SAP)
- API-level extraction (no database-level queries)
- Scheduled during off-peak hours (configurable in AppFlow)
- Specific entity access only (not “all SAP data”)
- Full CloudTrail audit logging of every extraction
When framed this way — as a read-only, API-based, audited, scheduled extraction — the approval conversation shifts from “no” to “which entities do you need?”
Barrier 3: “We Don’t Know How to Make SAP Data AI-Consumable”
The reality: SAP data is heavily structured — transaction codes, document numbers, currency amounts, material numbers. AI models expect natural language or semantically meaningful text. The gap between SAP’s structured format and AI’s consumption expectations is real.
The AWS solution: A transformation layer that converts structured SAP transactions into semantically meaningful text for embedding and AI consumption — while preserving the structured data for analytics.
# Glue ETL: Transform SAP procurement data into AI-consumable format
import boto3
from awsglue.context import GlueContext
from pyspark.context import SparkContext
from pyspark.sql.functions import concat_ws, col, lit, when
sc = SparkContext()
glueContext = GlueContext(sc)
# Read SAP purchase orders from S3 (landed by AppFlow)
po_data = glueContext.create_dynamic_frame.from_catalog(
database="sap_data_lake",
table_name="purchase_orders"
).toDF()
# Transform structured SAP data into semantic text for AI embedding
ai_ready = po_data.withColumn(
"semantic_text",
concat_ws(" ",
lit("Purchase Order"),
col("PurchaseOrder"),
lit("was created on"),
col("CreationDate"),
lit("for vendor"),
col("Supplier_Name"),
lit("with total value"),
col("PurchaseOrderNetAmount"),
col("DocumentCurrency"),
lit("containing"),
col("NumberOfItems"),
lit("line items for material group"),
col("MaterialGroup_Description"),
lit("with delivery date"),
col("DeliveryDate"),
lit("and current status"),
when(col("PurchasingProcessingStatus") == "02", lit("Approved"))
.when(col("PurchasingProcessingStatus") == "04", lit("Goods Received"))
.when(col("PurchasingProcessingStatus") == "06", lit("Invoice Received"))
.otherwise(lit("In Progress"))
)
)
# Write both formats:
# 1. Parquet (structured) — for analytics, Athena, Redshift
# 2. Semantic text — for Bedrock Knowledge Base, embeddings
# Structured for analytics
glueContext.write_dynamic_frame.from_options(
frame=DynamicFrame.fromDF(ai_ready, glueContext, "ai_ready"),
connection_type="s3",
connection_options={"path": "s3://enterprise-data-lake/sap/ai-ready/procurement/"},
format="parquet"
)
The dual-write pattern is the key design decision: the same data is available in structured format (for SQL analytics) and semantic format (for AI consumption). One extraction, two consumption patterns.
What Becomes Possible: AI Use Cases Powered by SAP Data
Once SAP data flows into your AWS AI platform, use cases that were previously impossible — or required weeks of manual analysis — become instant:
Use Case 1: Intelligent Procurement Insights
The question: “Which vendors have the highest rejection rates, and what is the financial impact of switching to alternatives?”
Without SAP-AI integration: A procurement analyst spends 2-3 days extracting data from SAP, building Excel models, cross-referencing quality records, and preparing a recommendation deck.
With SAP-AI integration: A Bedrock agent connected to SAP procurement history answers in seconds — grounded in actual goods receipt records, quality inspection results, and payment history spanning years.
Use Case 2: Cash Flow Forecasting
The question: “Based on our current open purchase orders, goods receipts pending invoice, and historical payment patterns, what is our expected cash outflow for the next 30/60/90 days?”
Without SAP-AI integration: Finance team manually runs SAP reports (ME2M, FBL1N), exports to Excel, applies assumptions, and builds a forecast. Takes 1-2 days each cycle.
With SAP-AI integration: An AI agent queries open PO data, historical payment terms compliance by vendor, and seasonal patterns — delivering a forecast in real-time that updates as new transactions post.
Use Case 3: Supplier Risk Early Warning
The question: “Are any of our critical suppliers showing patterns that indicate financial stress or delivery reliability issues?”
Without SAP-AI integration: Reactive — you discover supplier problems when deliveries are late or quality declines.
With SAP-AI integration: An AI agent monitors SAP transaction patterns continuously — increasing lead times, changing payment term requests, declining quality inspection pass rates — and alerts procurement before the risk materialises.
Use Case 4: Natural Language SAP Queries for Non-Technical Users
The question: Finance director asks “How much did we spend on logistics services in Q1 versus Q1 last year?”
Without SAP-AI integration: The finance director submits a request to the SAP reporting team, waits 2-3 days for a custom report.
With SAP-AI integration: Amazon Q Business, connected to SAP financial data in S3, answers the question immediately — in natural language, with source citations back to specific SAP document numbers.
The Architecture: SAP → AWS → AI
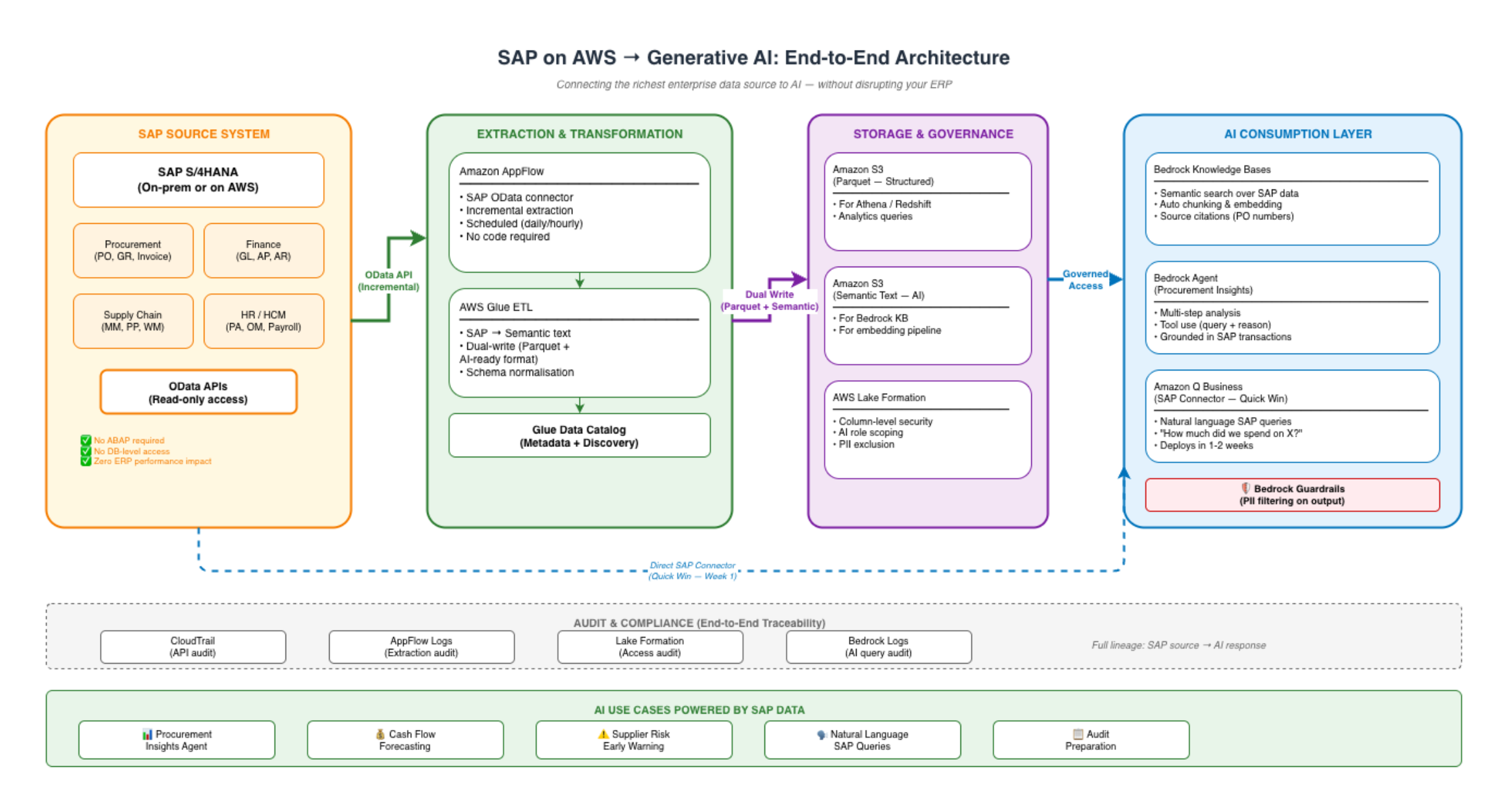
Amazon Q Business: The Quick Win
Amazon Q Business has a native SAP connector — meaning you can connect Q Business to SAP without building the full extraction pipeline first. For organisations wanting immediate value, Q Business provides natural language access to SAP data within weeks, not months.
The trade-off: Q Business provides conversational access but limited customisation. For advanced use cases (agents with tool use, custom reasoning, multi-step analysis), the full pipeline (AppFlow → S3 → Bedrock Knowledge Base → Bedrock Agent) gives you maximum flexibility.
My recommendation: Deploy Q Business with the SAP connector as Week 1 value demonstration. Build the full pipeline in parallel for advanced use cases. This gives stakeholders immediate evidence of AI-over-SAP value while the engineering team builds the production architecture.
The Business Case: SAP-AI Integration Economics
What Changes When AI Can Query SAP
| Business Function |
Current State (Manual) |
AI-Enabled State |
Time Savings |
| Procurement analysis |
2-3 days per report |
Real-time agent response |
90%+ |
| Cash flow forecasting |
1-2 days per cycle |
Continuous, auto-updating |
85%+ |
| Vendor performance review |
Quarterly (manual compilation) |
Continuous monitoring with alerts |
From reactive to proactive |
| Ad-hoc SAP queries |
2-3 day turnaround from SAP team |
Instant via Q Business |
95%+ |
| Audit preparation |
2-4 weeks |
Days (AI retrieves evidence instantly) |
80%+ |
Implementation Cost
| Component |
Cost |
Timeline |
| AppFlow SAP connector setup |
$5K-$15K |
1-2 weeks |
| Glue ETL for AI transformation |
$10K-$25K |
2-3 weeks |
| Bedrock Knowledge Base on SAP data |
$5K-$10K |
1 week |
| Q Business with SAP connector |
$20/user/month |
1-2 weeks |
| Lake Formation governance |
$10K-$20K |
2-3 weeks |
| Total initial investment |
$30K-$70K |
6-10 weeks |
ROI Drivers
- Procurement team productivity: 2-3 analysts each saving 1-2 days/week on manual SAP reporting = $60K-$80K/year in recovered capacity
- Faster decision-making: Cash flow forecasts available daily instead of monthly = better working capital management
- Risk avoidance: Early supplier risk detection prevents supply chain disruptions ($50K-$150K per incident avoided)
- Audit efficiency: 80% reduction in audit preparation time = $20K-$40K/year
Typical first-year ROI: 2-3x the initial investment — driven primarily by the productivity gains of giving finance and procurement teams natural language access to data they currently wait days to receive.
A Presales Perspective: Positioning SAP-AI in Customer Conversations
Why This Conversation Is Uniquely Powerful
Most AI presales conversations compete with dozens of other vendors offering generic AI capabilities. The SAP-AI conversation has no competition — because it requires specific expertise that few partners possess:
- Deep SAP knowledge — understanding the data model, OData services, extraction patterns
- AWS AI expertise — Bedrock, Knowledge Bases, Q Business, AppFlow
- Enterprise integration experience — governance, security, performance considerations
Partners who can credibly deliver all three are rare. That scarcity is the positioning advantage.
The Opening Question
“Your SAP system contains ten years of procurement, financial, and operational transaction data. Today, how long does it take someone in finance or procurement to get an answer from that data?”
The answer is always “days” or “we have to ask the SAP team.” That gap — between the value of the data and the accessibility of it — is the opportunity.
The Demonstration That Wins
Show Q Business answering a question about the customer’s own SAP data (in a demo environment): “What were our top 10 vendors by spend last quarter, and which of them had delivery delays exceeding 5 days?”
When a CFO sees that question answered in 3 seconds instead of 3 days, the business case conversation is over. The only remaining question is timeline.
The Objection You Will Hear
“We’re planning to move to S/4HANA — shouldn’t we wait?”
Response: “The AI platform we build today works identically whether your SAP is ECC or S/4HANA. AppFlow connects to both via OData. If anything, building AI-over-SAP now gives you a compelling reason to accelerate the S/4HANA migration — because S/4HANA’s improved APIs make AI integration even simpler. You are not building throwaway work — you are building the AI layer that survives the migration.”
Governance: What the CISO Needs to Hear
SAP data is among the most sensitive in the enterprise — financial records, vendor contracts, employee information. The CISO will rightfully scrutinize any AI system that touches it.
The governance architecture that addresses their concerns:
- Read-only extraction: AppFlow pulls data via OData with a service account that has zero write permissions in SAP. The AI can never modify ERP data.
- Lake Formation scoping: The AI service role sees only approved SAP entities — purchase orders and vendor master, for example — not HR compensation or financial postings.
- Column exclusion: Sensitive fields (bank account numbers, personal IDs, salary data) are excluded at the Glue transformation layer — they never enter the AI-accessible S3 path.
- Bedrock Guardrails: Output-layer protection ensures the AI does not surface financial amounts or vendor names that the requesting user is not authorised to see.
- Full audit trail: CloudTrail logs every AppFlow extraction, every Bedrock query, every S3 access — creating a complete lineage from SAP source to AI response.
The message: “The AI has less access to SAP data than your average SAP power user. It sees a governed subset, it can only read, and every access is logged.”
Lessons for Technology Leaders
- Your ERP is your AI moat — but only if you connect it — Every competitor has access to the same foundation models. None of them have your SAP transaction history. The enterprise that connects AI to SAP data first builds an insight advantage that compounds with every month of history.
- Start with Q Business for quick wins, build the full pipeline for advanced use cases — Q Business with the SAP connector demonstrates value in weeks. The full architecture (AppFlow → S3 → Bedrock) enables agent-level AI that Q Business alone cannot deliver. Run both in parallel.
- The SAP team is an ally, not a blocker — frame it correctly — Read-only API access, scheduled off-peak, specific entities only, fully audited. When framed as “we need to read purchase orders via OData,” the conversation is straightforward. When framed as “we need access to SAP,” it sounds terrifying. Language matters.
- Dual-write architecture serves both analytics and AI — The same extraction pipeline feeds structured data (for Athena/Redshift analytics) and semantic data (for Bedrock AI). One investment, two value streams.
- SAP-AI integration is a rare skill combination — and a presales differentiator — Most AWS partners cannot credibly deliver SAP + AI. Most SAP partners cannot credibly deliver AWS AI. The partner that delivers both wins deals that neither competitor can contest. That intersection is where the highest-value enterprise conversations happen.
About the Author
Rajat Jindal is VP – Presales at AeonX Digital Technology Limited, where he architects winning cloud strategies for enterprise customers and translates modernization into measurable business value. He is a strong advocate of AWS, committed to sharing thought leadership that helps technology leaders make faster, better-informed decisions.
by Rajat Jindal | May 7, 2026 | AWS
The Governance Conversation Nobody Wants to Have Before Deploying AI
Every enterprise wants AI deployed yesterday. The board is asking about it. Competitors are shipping it. The pressure to demonstrate AI capability is immense.
But here is what I observe in presales engagements every week: the enterprises that deploy AI fastest are not the ones that skip governance — they are the ones that solved governance first. The ones that skip it deploy a POC in four weeks, then spend six months in a compliance review that blocks production deployment indefinitely.
Governance is not the brake on AI adoption. The absence of governance is.
When a CISO asks “What data can this AI system access?”, the answer cannot be “everything in the data lake.” When a DPO asks “Can this AI surface PII in its responses?”, the answer cannot be “we’ll add guardrails later.” When the board asks “Who is accountable if the AI makes a decision based on data it should not have seen?”, silence is not an option.
AWS Lake Formation answers these questions architecturally — not through policy documents that nobody reads, but through enforced permissions that AI systems cannot bypass. This post is about why governance is the enabler that gets AI from POC to production, and how Lake Formation provides the technical implementation that satisfies security, compliance, and the board simultaneously.
Why AI Without Governance Is a Ticking Clock
The Fundamental Problem
Traditional application access control is simple: User A has access to System B. If User A opens System B, they see the data. If they do not have access, they cannot open it.
AI breaks this model completely. An AI system does not access data on behalf of a single user — it indexes, retrieves, and surfaces data to multiple users with different permission levels. A Bedrock Knowledge Base might index HR data, customer data, financial data, and product documentation in the same vector store. When User A asks a question, the AI must know which of those data sources User A is permitted to see — and return only results that respect those boundaries.
Without governance, one of two things happens:
- Over-restriction: The security team restricts AI access to the safest possible dataset (public knowledge base articles only), making the AI useless for anything beyond what Google could answer. Adoption dies.
- Under-restriction: The AI team gives the system broad access to demonstrate value, and six months later someone discovers that a junior employee’s AI assistant can surface executive compensation data, M&A strategy documents, or customer PII. The CISO shuts it down.
Both outcomes kill AI adoption. Governance prevents both by making fine-grained, permission-aware AI the default state — not an afterthought.
Real-World Governance Failures I Have Observed
Without naming specific customers, these are patterns I have seen repeated across industries:
- The HR data leak: An internal productivity AI was connected to a SharePoint instance that included HR performance reviews. A team lead asked the AI “How is my team performing?” and received a response that included verbatim quotes from confidential performance improvement plans. Deployed Monday, shut down Wednesday.
- The financial data surface: An AI assistant connected to a data lake surfaced quarterly revenue forecasts in response to a sales rep’s question about deal sizing. The forecasts were draft numbers not yet approved by finance. One email to a customer later, the organisation had a material disclosure concern.
- The cross-customer bleed: A customer support AI indexed all support tickets without customer-level access isolation. A customer asking “What similar issues have others experienced?” received details from competitor companies’ support tickets — including company names.
Every one of these was preventable with proper data governance applied before AI deployment, not after.
Lake Formation is not a new service — it launched in 2019. But its relevance has transformed. In 2019, it governed who could query your data warehouse. In 2026, it governs what your AI systems can see, surface, and reference. That is a fundamentally different — and more critical — function.
| Capability |
What It Controls |
Why AI Needs It |
| Table-level permissions |
Which tables a principal can access |
AI service roles get access only to approved data domains |
| Column-level security |
Which columns within a table are visible |
Salary, SSN, credit card columns hidden from AI roles |
| Row-level security |
Which rows are returned based on filter conditions |
AI serving Customer A sees only Customer A’s data |
| Tag-based access control |
Permissions assigned by metadata tags, not individual resources |
“PII=true” tag automatically restricts AI access without per-table configuration |
| Data location permissions |
Which S3 locations a principal can register and access |
AI embedding pipelines cannot process data from restricted locations |
The Key Insight: AI Systems Are Principals
The architectural shift that makes Lake Formation critical for AI: treat every AI system as an IAM principal with scoped permissions — exactly as you would treat a human user or application.
Your Bedrock Knowledge Base runs under an IAM role. That role is a Lake Formation principal. You grant it access to specific databases, tables, and columns — nothing more. When the Knowledge Base indexes data, it can only index what its role permits. When it retrieves data for a user query, it can only return data its role can see.
This is not a bolt-on. It is the same governance model that already controls your data lake — extended to AI identities.
Implementation: Four Governance Patterns for AI
Pattern 1: Domain-Scoped AI Access
The most common pattern: each AI application gets access only to its business domain.
# Customer Support AI — access ONLY to support-domain data
aws lakeformation grant-permissions \
--principal '{
"DataLakePrincipalIdentifier": "arn:aws:iam::<account-id>:role/SupportAI-KnowledgeBaseRole"
}' \
--resource '{
"Database": {
"Name": "support_domain"
}
}' \
--permissions '["DESCRIBE"]'
aws lakeformation grant-permissions \
--principal '{
"DataLakePrincipalIdentifier": "arn:aws:iam::<account-id>:role/SupportAI-KnowledgeBaseRole"
}' \
--resource '{
"Table": {
"DatabaseName": "support_domain",
"TableWildcard": {}
}
}' \
--permissions '["SELECT", "DESCRIBE"]'
# EXPLICITLY DENY: HR, Finance, Legal domains
# (Lake Formation denies by default — no grant = no access)
# The support AI role has NO grants on hr_domain, finance_domain, or legal_domain
# Therefore it cannot index or retrieve data from those domains
The “deny by default” property of Lake Formation is what makes this secure: you grant what is permitted, and everything else is automatically inaccessible. No AI system can access data that has not been explicitly granted to its role.
Pattern 2: Column-Level PII Protection
Even within permitted tables, sensitive columns should be invisible to AI systems that do not require them.
# Grant the AI role access to the customer_interactions table
# BUT exclude PII columns (email, phone, address)
aws lakeformation grant-permissions \
--principal '{
"DataLakePrincipalIdentifier": "arn:aws:iam::<account-id>:role/SupportAI-KnowledgeBaseRole"
}' \
--resource '{
"TableWithColumns": {
"DatabaseName": "support_domain",
"Name": "customer_interactions",
"ColumnNames": [
"ticket_id",
"subject",
"body",
"resolution_status",
"interaction_type",
"created_at",
"product_category"
]
}
}' \
--permissions '["SELECT"]'
# Columns NOT listed (customer_email, customer_phone, customer_address)
# are invisible to the AI — it cannot index, retrieve, or surface them
This is defence-in-depth for AI: even if the AI is asked “What is this customer’s email?”, it literally cannot answer — the column does not exist in its view of the data. The protection is architectural, not prompt-based.
Pattern 3: Row-Level Security for Multi-Tenant AI
For SaaS platforms or multi-customer environments, AI must be isolated per tenant — Customer A’s AI cannot see Customer B’s data.
# Create a data filter that restricts to a specific customer
aws lakeformation create-data-cells-filter \
--table-data '{
"TableCatalogId": "<account-id>",
"DatabaseName": "support_domain",
"TableName": "customer_interactions",
"Name": "customer-acme-filter",
"RowFilter": {
"FilterExpression": "customer_org_id = '\''ACME-001'\''"
},
"ColumnWildcard": {}
}'
# Grant the ACME-specific AI role access through this filter
aws lakeformation grant-permissions \
--principal '{
"DataLakePrincipalIdentifier": "arn:aws:iam::<account-id>:role/ACME-AI-Role"
}' \
--resource '{
"DataCellsFilter": {
"TableCatalogId": "<account-id>",
"DatabaseName": "support_domain",
"TableName": "customer_interactions",
"Name": "customer-acme-filter"
}
}' \
--permissions '["SELECT"]'
With this pattern, ACME’s AI assistant queries the same table but sees only ACME’s rows. The isolation is enforced at the storage layer — not in the application logic, not in the prompt, not in the AI’s instructions. It is physically impossible for the AI to return another customer’s data.
Pattern 4: Tag-Based Governance at Scale
For enterprises with hundreds of tables and dozens of AI applications, per-table grants become unmanageable. Tag-based access control solves this — assign tags to data, assign tag permissions to roles, and governance scales automatically as new data is added.
# Define governance tags
aws lakeformation create-lf-tag \
--tag-key "data_classification" \
--tag-values '["public", "internal", "confidential", "restricted"]'
aws lakeformation create-lf-tag \
--tag-key "ai_approved" \
--tag-values '["yes", "no", "pending_review"]'
# Tag tables with their classification
aws lakeformation add-lf-tags-to-resource \
--resource '{
"Table": {
"DatabaseName": "support_domain",
"Name": "knowledge_articles"
}
}' \
--lf-tags '[
{"TagKey": "data_classification", "TagValues": ["internal"]},
{"TagKey": "ai_approved", "TagValues": ["yes"]}
]'
aws lakeformation add-lf-tags-to-resource \
--resource '{
"Table": {
"DatabaseName": "hr_domain",
"Name": "employee_compensation"
}
}' \
--lf-tags '[
{"TagKey": "data_classification", "TagValues": ["restricted"]},
{"TagKey": "ai_approved", "TagValues": ["no"]}
]'
# Grant AI role access based on tags — not individual tables
aws lakeformation grant-permissions \
--principal '{
"DataLakePrincipalIdentifier": "arn:aws:iam::<account-id>:role/EnterpriseAI-Role"
}' \
--resource '{
"LFTagPolicy": {
"ResourceType": "TABLE",
"Expression": [
{"TagKey": "ai_approved", "TagValues": ["yes"]},
{"TagKey": "data_classification", "TagValues": ["public", "internal"]}
]
}
}' \
--permissions '["SELECT", "DESCRIBE"]'
The power of this pattern: when a new table is added to the data lake and tagged ai_approved=yes and data_classification=internal, the AI automatically gains access — no manual grant required. When a table is tagged ai_approved=no, the AI is automatically excluded. Governance scales with your data, not with your team’s capacity to manage permissions.
Lake Formation controls what data the AI can access. Bedrock Guardrails controls what the AI can output. Together, they form a two-layer defence:
| Layer |
Controls |
Prevents |
| Lake Formation (data access) |
What data the AI can index and retrieve |
AI cannot see restricted data — it does not exist in its context |
| Bedrock Guardrails (output filtering) |
What the AI can include in responses |
Even if data leaks into context, PII is anonymised or blocked at output |
{
"name": "enterprise-ai-output-guardrail",
"description": "Second layer: filter outputs even if data access governance has gaps",
"sensitiveInformationPolicyConfig": {
"piiEntitiesConfig": [
{"type": "EMAIL", "action": "ANONYMIZE"},
{"type": "PHONE", "action": "ANONYMIZE"},
{"type": "CREDIT_DEBIT_CARD_NUMBER", "action": "BLOCK"},
{"type": "AWS_ACCESS_KEY", "action": "BLOCK"},
{"type": "ADDRESS", "action": "ANONYMIZE"}
]
},
"topicPolicyConfig": {
"topicsConfig": [
{
"name": "employee-compensation",
"definition": "Questions about employee salaries, bonuses, equity grants, or total compensation",
"type": "DENY"
},
{
"name": "unreleased-financials",
"definition": "Questions about quarterly results, forecasts, or financial data not yet publicly disclosed",
"type": "DENY"
}
]
}
}
The principle: assume each layer might have gaps, and design so that both layers must fail simultaneously for a governance breach to occur. Lake Formation prevents the AI from seeing restricted data. Guardrails prevent the AI from outputting sensitive information even if it somehow enters the context. Neither layer alone is sufficient — together they are robust.
The Business Case: Governance as AI Accelerator
The Counterintuitive Truth
Every enterprise I work with assumes governance slows AI deployment. The data proves the opposite:
| Approach |
Time to POC |
Time to Production |
Total |
| AI first, governance later |
4 weeks |
6-12 months (stuck in compliance review) |
7-13 months |
| Governance first, AI second |
6 weeks |
2-4 weeks (compliance pre-approved) |
8-10 weeks |
The governance-first approach is 3-5x faster to production — because the compliance review happens once, during design, and all subsequent AI deployments inherit the approved governance model without repeating the review.
The Cost of Governance Failure
| Incident Type |
Average Cost |
Preventable With |
| PII exposure through AI (GDPR/DPDP) |
$100K-$500K (fines + remediation) |
Column-level security |
| Cross-customer data leak |
$150K-$500K (contractual liability + trust) |
Row-level security |
| AI deployment shutdown by compliance |
$100K-$200K (wasted engineering effort) |
Pre-approved governance model |
| Re-engineering AI for governance after deployment |
$100K-$250K (retrofit cost) |
Governance-first design |
The Governance-First ROI
- Governance implementation cost: $30K-$60K (Lake Formation setup, tag taxonomy, role design)
- Cost avoided per AI deployment: $80K-$150K (compliance review, retrofit, delay)
- Break-even: First AI deployment
- Year-one value (3-5 AI deployments): $200K-$500K in avoided delays and rework
A Presales Perspective: Making Governance the Hero of the AI Conversation
The Mistake Most Sellers Make
In AI presales, the natural instinct is to demonstrate the AI capability — show the chatbot answering questions, show the agent reasoning, show the knowledge base retrieving relevant documents. This impresses the CTO and the AI team.
But the person who blocks production deployment is the CISO, the DPO, or the legal team. They were not in the demo room. And when they review the architecture, their first question is: “What controls data access?”
I have learned to invite the CISO to the first demo — not the fifth. And I lead with governance, not capability.
The Three-Slide Governance Story
Slide 1: “Here is what the AI CAN see” — show Lake Formation grants, scoped to specific domains and tables. The CISO’s concern is “what if it sees everything?” Showing explicit, limited grants addresses this immediately.
Slide 2: “Here is what the AI CANNOT see” — show the deny-by-default model. Everything not explicitly granted is invisible. Show that HR, finance, and legal domains have zero grants to the AI role.
Slide 3: “Here is what happens if something slips through” — show Bedrock Guardrails as the second layer. Even if governance has a gap, PII is anonymised and sensitive topics are blocked at output.
After those three slides, the CISO becomes an advocate for the project rather than a blocker. They have seen the controls. They understand the model. The compliance review takes days, not months.
The Discovery Question
“If your AI system had access to your entire data lake today — every table, every column, every document — would your CISO be comfortable? If not, what would need to be true for them to approve production deployment?”
That question surfaces the governance requirements without me having to guess them. The customer tells me exactly what controls they need. I map those controls to Lake Formation capabilities. The conversation becomes collaborative, not adversarial.
The Governance Maturity Model for AI
| Level |
Description |
Lake Formation Usage |
AI Readiness |
| 0 — No governance |
All IAM principals have broad S3 access |
Not deployed |
❌ AI deployment will be blocked |
| 1 — Basic |
Database-level permissions, no column/row security |
Table grants only |
⚠️ AI can access too much within permitted databases |
| 2 — Intermediate |
Column-level security, PII columns excluded from AI |
Column filtering active |
✅ AI deployable for non-sensitive use cases |
| 3 — Advanced |
Row-level security, tag-based access, multi-tenant isolation |
Full feature usage |
✅ AI deployable across all use cases including regulated |
| 4 — Automated |
New data auto-governed via tags, AI access auto-scoped |
Tags + automation |
✅ AI scales without governance bottleneck |
Most enterprises I assess are at Level 0 or 1. Getting to Level 2 takes 4-6 weeks and unlocks AI deployment immediately. Getting to Level 3 takes 8-12 weeks and unlocks regulated/multi-tenant AI. The investment is modest relative to the deployment velocity it enables.
Lessons for Technology Leaders
- Governance is not the brake on AI — it is the accelerator — Enterprises that solve governance first deploy AI to production 3-5x faster than those who defer it. The compliance review either happens proactively (weeks) or reactively (months). Choose proactively.
- Treat AI systems as IAM principals with scoped permissions — Every Bedrock Knowledge Base, every agent, every Q Business instance runs under a role. Govern that role with Lake Formation exactly as you govern human access. Same model, same tools, same audit trail.
- Column-level security is the minimum viable AI governance — If your AI can see PII columns, it will eventually surface PII. Removing those columns from the AI’s view is a 30-minute configuration change that prevents a $100K+ incident. Do it today.
- Tag-based governance is the only model that scales — Per-table grants work for 10 tables. At 100+ tables, they become unmanageable. Tags let governance scale with your data — new tables inherit permissions automatically based on their classification.
- Defence-in-depth is not optional for enterprise AI — Lake Formation at the data layer AND Guardrails at the output layer. Either can have gaps. Both failing simultaneously is a governance architecture failure, not a single-point failure. Design for that redundancy.
- Invite the CISO to the first AI demo, not the fifth — The person who blocks production deployment should see the governance controls from day one. Early inclusion makes them an advocate. Late inclusion makes them a blocker.
About the Author
Rajat Jindal is VP – Presales at AeonX Digital Technology Limited, where he architects winning cloud strategies for enterprise customers and translates modernization into measurable business value. He is a strong advocate of AWS, committed to sharing thought leadership that helps technology leaders make faster, better-informed decisions.
by Rajat Jindal | Apr 23, 2026 | AWS
The Pipeline Problem Nobody Talks About in Board Meetings
Every enterprise I work with has the same invisible cost centre: ETL pipelines. Hundreds of them. Running nightly. Breaking silently. Consuming 30-40% of data engineering capacity not to create value, but to move data from where it is to where it needs to be.
ETL — Extract, Transform, Load — was a necessary evil in a world where operational databases and analytics systems were architecturally incompatible. You could not run an analytical query against your production MySQL database without degrading customer-facing performance. So you moved the data. Every night. Through fragile, hand-coded pipelines that nobody fully understood and everybody feared changing.
In 2026, this model is not just expensive — it is architecturally incompatible with AI. AI agents need fresh data. Embedding pipelines need real-time updates. Knowledge Bases need to reflect the current state of your business, not last night’s snapshot. Every hour of ETL latency is an hour where your AI is answering questions with stale information — and stale AI answers erode user trust faster than no AI at all.
AWS Zero-ETL integrations eliminate this entire layer. Not by building better pipelines — by eliminating the need for pipelines altogether. Data flows continuously from operational sources to analytics and AI destinations without any pipeline code, scheduling infrastructure, or failure-mode complexity.
This post is about the strategic implications of that shift — and why the enterprises that adopt Zero-ETL first will free 30-40% of their data engineering capacity for AI innovation instead of pipeline maintenance.
Why ETL Pipelines Are the Silent Tax on Every AI Initiative
The Hidden Cost
In every data & AI presales discovery I run, I ask the same question: “What percentage of your data engineering team’s time is spent building and maintaining data movement pipelines versus building AI features or analytical capabilities?”
The answer, consistently, across industries: 30-50%. Sometimes higher.
That is not engineering time spent creating business value. It is engineering time spent ensuring that data arrives at the right place, in the right format, at the right time — work that has zero business differentiation. Every enterprise runs similar pipelines. None of them gain competitive advantage from having better COPY commands.
The Freshness Problem
ETL pipelines run on schedules — typically nightly. That means:
- Your analytics dashboard shows yesterday’s state, not today’s
- Your AI agent answers questions based on data that is 8-24 hours stale
- Your embedding pipeline generates vectors from last night’s snapshot, missing today’s customer interactions entirely
For traditional BI, nightly freshness was acceptable. For AI systems that users interact with in real-time, it creates a trust problem. When an employee asks “What is this customer’s current status?” and the AI answers based on yesterday’s data, that employee stops trusting the AI after the second incorrect answer.
The Fragility Problem
Every ETL pipeline is a potential failure point:
- Schema changes in the source database break the pipeline silently
- Network issues between source and destination create data gaps that go undetected for days
- Resource contention during peak ETL windows slows both the pipeline and production workloads
- A single failed dependency in a pipeline DAG can cascade and delay the entire data platform
The operations overhead of monitoring, alerting, retrying, and debugging ETL failures is substantial — and it scales linearly with the number of pipelines. More data sources = more pipelines = more fragility = more engineering time spent on maintenance.
What Zero-ETL Actually Means: A Technical and Strategic Definition
Zero-ETL is not “better ETL.” It is the architectural elimination of the pipeline layer entirely.
With Zero-ETL integrations, data replicates continuously from the operational source to the analytics or AI destination using native AWS infrastructure. There is no pipeline code to write. No scheduler to configure. No failure modes to handle. No transformation jobs to maintain.
How It Works (Architecturally)
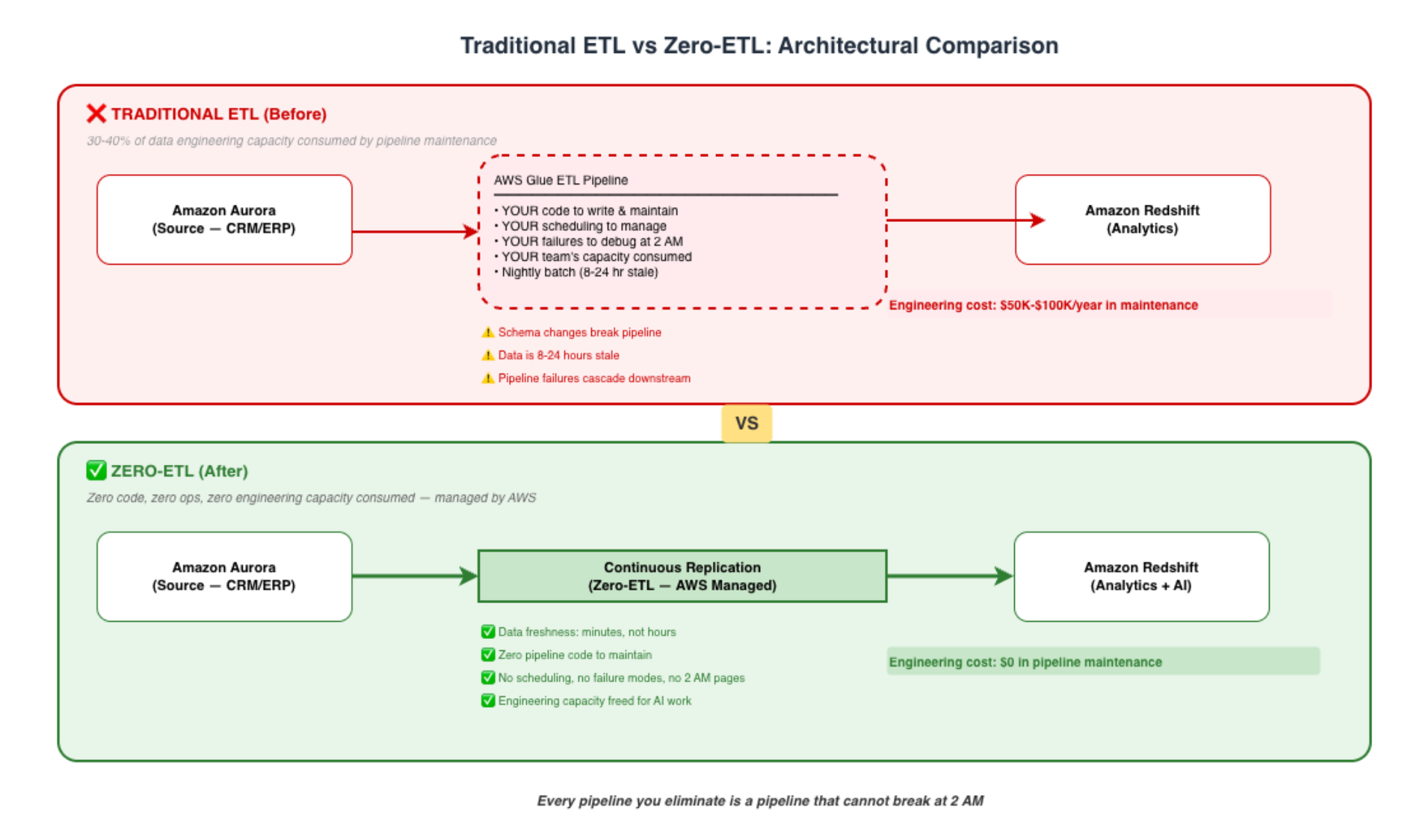
Available Zero-ETL Integrations on AWS (as of early 2026)
| Source |
Destination |
Use Case |
| Amazon Aurora MySQL |
Amazon Redshift |
Operational data → analytics without pipelines |
| Amazon Aurora PostgreSQL |
Amazon Redshift |
Same — for PostgreSQL workloads |
| Amazon RDS for MySQL |
Amazon Redshift |
Non-Aurora RDS → analytics |
| Amazon DynamoDB |
Amazon Redshift |
NoSQL operational data → SQL analytics |
| Amazon DynamoDB |
Amazon OpenSearch |
NoSQL data → search and vector search |
| Amazon Aurora |
Amazon OpenSearch |
Relational data → search (including semantic) |
The Strategic Implication
Every integration in that table eliminates one or more ETL pipelines — plus the scheduling, monitoring, alerting, and debugging infrastructure around them. For a mid-market enterprise with 20-50 ETL pipelines, Zero-ETL can eliminate 30-60% of them within a single quarter.
The AI Angle: Why Zero-ETL Is an AI Enablement Strategy
Zero-ETL is typically discussed as an analytics optimisation. That undersells it dramatically. For enterprises deploying AI, Zero-ETL is a freshness and velocity strategy that directly impacts AI quality.
Freshness Enables AI Trust
When Aurora transactional data flows continuously to Redshift (and from there to Bedrock Knowledge Bases), your AI is always grounded in current state. The customer who placed an order 10 minutes ago appears in the AI’s answers immediately — not tomorrow morning after the nightly batch runs.
This matters enormously for:
- Customer-facing AI: “What’s the status of my order?” must reflect the current state
- Internal copilots: “What’s our pipeline this quarter?” must include today’s deals
- AI agents: Autonomous agents making decisions on stale data make wrong decisions
Velocity Enables AI Experimentation
The most expensive property of AI development is iteration speed. When every new AI use case requires a new ETL pipeline to get data into the right format and place, the cycle time for each experiment is weeks. When data is already available in Redshift and OpenSearch via Zero-ETL, a new AI use case requires only a Bedrock Knowledge Base configuration — deployable in hours.
Example: CRM Data Flowing to AI Without Pipelines
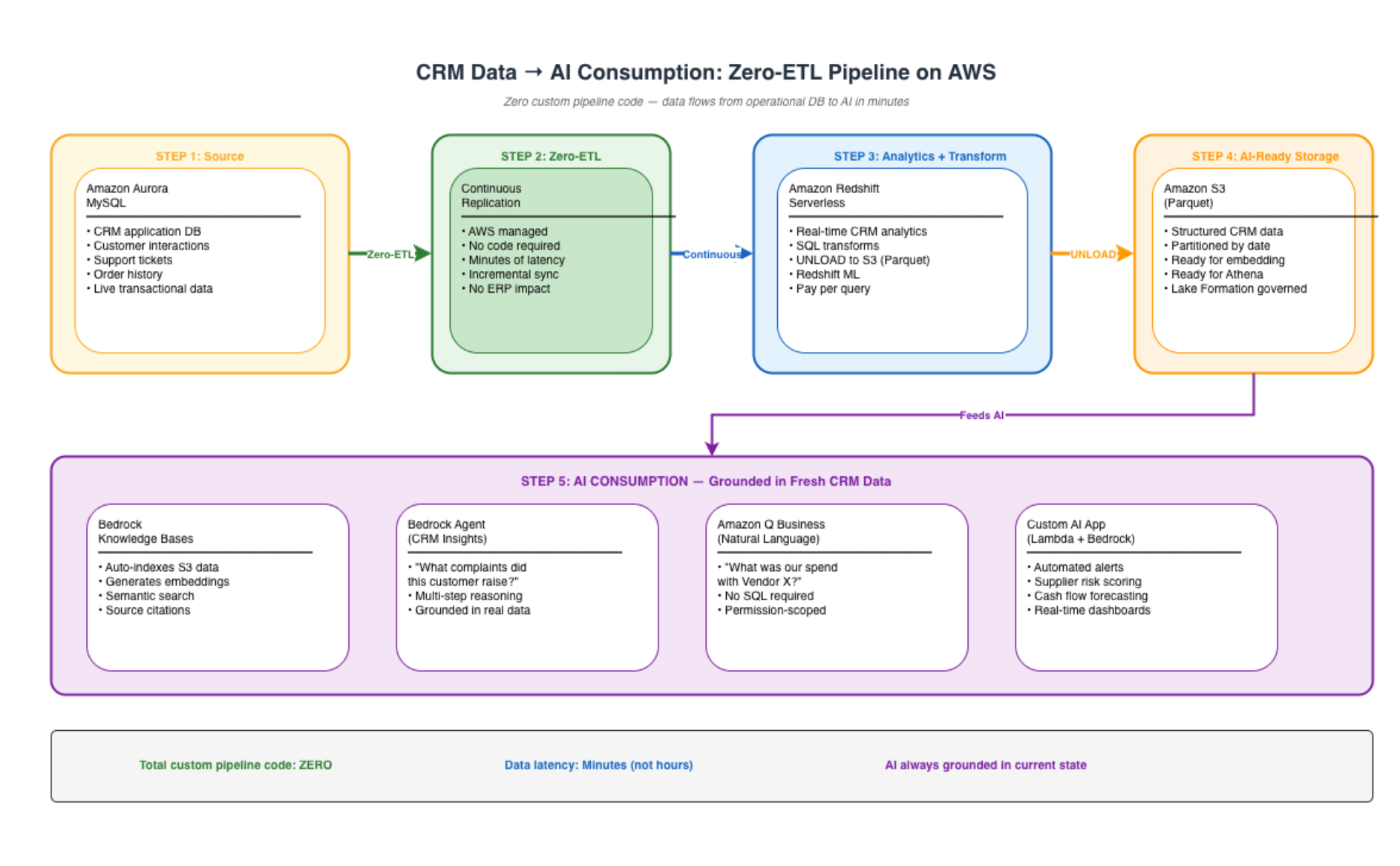
In this pattern, CRM data flows from Aurora to Redshift via Zero-ETL (zero code), then from Redshift to S3 via scheduled UNLOAD (one command), then into Bedrock Knowledge Bases for AI consumption. Total custom pipeline code: zero. Total latency: minutes, not hours.
Implementation: Setting Up Zero-ETL (Aurora → Redshift)
# Create a Zero-ETL integration from Aurora MySQL to Redshift
aws rds create-integration \
--integration-name crm-zero-etl \
--source-arn arn:aws:rds:ap-south-1:<account-id>:cluster:crm-aurora-cluster \
--target-arn arn:aws:redshift-serverless:ap-south-1:<account-id>:namespace/<namespace-id> \
--tags Key=Environment,Value=Production Key=Purpose,Value=AI-Analytics
Step 2: Authorise the Integration on Redshift
-- Run in Redshift: create the database from the integration
CREATE DATABASE crm_realtime FROM INTEGRATION '<integration-id>';
-- Data is now continuously available — query it immediately
SELECT customer_id, interaction_type, created_at
FROM crm_realtime.public.customer_interactions
WHERE created_at > CURRENT_DATE - INTERVAL '1 hour';
Step 3: Feed AI From Redshift
-- Unload fresh CRM data to S3 for Bedrock Knowledge Base consumption
UNLOAD ('
SELECT customer_id, subject, body, resolution_status, created_at
FROM crm_realtime.public.customer_interactions
WHERE created_at > CURRENT_DATE - INTERVAL ''1 day''
')
TO 's3://data-lake-ai-ready/crm/daily/'
IAM_ROLE 'arn:aws:iam::<account-id>:role/RedshiftUnloadRole'
FORMAT PARQUET
ALLOWOVERWRITE;
This three-step pattern — Zero-ETL into Redshift, UNLOAD to S3, Bedrock Knowledge Base on S3 — gives you a continuously fresh AI data pipeline with zero custom ETL code.
The Business Case: Pipeline Elimination Economics
What You Stop Paying For
| Eliminated Cost |
Annual Savings (Mid-Market) |
Notes |
| Glue job compute (nightly batch ETL) |
$15K-$40K/year |
Depends on data volume and job complexity |
| Data engineer pipeline maintenance (30-40% of time) |
$50K-$100K/year |
1-2 FTE equivalent redirected to AI work |
| Incident response for pipeline failures |
$15K-$30K/year |
On-call time, investigation, remediation |
| Data freshness penalty (stale dashboards, stale AI) |
Unquantified but material |
Decisions made on old data have compounding cost |
| Total pipeline elimination value |
$80K-$170K/year |
— |
What You Start Paying For
| Zero-ETL Cost |
Annual Cost |
Notes |
| Zero-ETL integration (Aurora → Redshift) |
Included in Redshift pricing |
No separate charge for the integration itself |
| Redshift Serverless compute |
$30K-$80K/year |
Usage-based — pay for what you query |
| Net savings |
$15K-$130K/year |
Plus engineering capacity freed for AI |
The real ROI is not the infrastructure savings — it is the engineering capacity. Every data engineer freed from pipeline maintenance is a data engineer who can build AI features, train models, or optimise data quality. That reallocation is what accelerates AI adoption.
A Presales Perspective: Positioning Zero-ETL in Customer Conversations
The Question That Opens the Conversation
“How many ETL pipelines does your data team maintain today? And how many of them broke in the last 30 days?”
The first number is usually 20-100. The second number makes the room uncomfortable. That discomfort is the opening.
The Framing That Resonates
For CTOs: “Every pipeline is technical debt that consumes engineering capacity you could be spending on AI. Zero-ETL eliminates that debt category-by-category.”
For CDOs: “Your data freshness SLA is limited by your slowest pipeline. Zero-ETL makes freshness an infrastructure property, not an engineering challenge.”
For CFOs: “You are paying senior data engineers $150K-$200K to maintain COPY commands that AWS will run for you at infrastructure cost. That is a misallocation of your most expensive resource.”
The Objection You Will Hear
“We have custom transformations in our ETL — Zero-ETL can’t replace those.”
Response: “Correct. Zero-ETL replaces the data movement layer — the extract and load. Your custom transformation logic moves to Redshift (SQL transforms, Redshift ML) or to downstream processing. The transformation is still yours — you just stop paying for the plumbing around it.”
Not every pipeline disappears. But the 40-60% that are pure data movement with minimal transformation — those are immediately eliminable. Start there.
When to Use Zero-ETL vs Traditional Approaches
| Scenario |
Recommendation |
Why |
| Aurora/RDS data needed in Redshift for analytics + AI |
Zero-ETL |
Eliminates pipeline entirely |
| DynamoDB data needed for search/AI |
Zero-ETL to OpenSearch |
Enables vector search without ETL |
| Complex multi-source joins and transformations |
Glue ETL (keep) |
Transformation logic still needs code |
| Real-time streaming from external sources |
Kinesis + Glue Streaming |
Zero-ETL is for AWS-to-AWS sources |
| One-time historical data migration |
AWS DMS |
Zero-ETL is for ongoing replication |
Zero-ETL does not replace all pipelines. It replaces the ones that should never have been pipelines in the first place — pure data replication between AWS services that historically required engineering effort for no differentiated value.
The 12-Month Roadmap: From Pipeline-Heavy to Zero-ETL
| Month |
Action |
Outcome |
| 1 |
Audit existing pipelines — categorise as “pure movement” vs “transformation” |
Know which pipelines are eliminable |
| 2-3 |
Enable Zero-ETL for primary Aurora → Redshift flows |
3-5 pipelines eliminated, data freshness improved to minutes |
| 4-5 |
Migrate DynamoDB → OpenSearch pipelines to Zero-ETL |
Search and vector search fed automatically |
| 6-8 |
Connect Redshift to Bedrock Knowledge Bases via S3 UNLOAD |
AI consumption without custom integration |
| 9-12 |
Redeploy freed engineering capacity to AI use cases |
Data engineers building AI features, not maintaining pipes |
Lessons for Technology Leaders
- Every pipeline you eliminate is a pipeline that cannot break at 2 AM — Reliability is not about building better monitoring for your pipelines. It is about having fewer pipelines to monitor.
- Zero-ETL is a capacity strategy, not just a cost strategy — The $15K-$40K in Glue savings matters less than the $60K-$120K in engineering time redirected from maintenance to AI innovation.
- Data freshness is an AI quality metric — When your AI answers questions based on yesterday’s data, users stop trusting it. Zero-ETL’s continuous replication keeps AI grounded in current state.
- Not every pipeline should be Zero-ETL — Complex multi-source transformations still need Glue or custom code. But pure data replication (40-60% of most enterprise pipelines) should never be custom code. Eliminate those first.
- The CTO who says “our pipelines work fine” has not asked their data engineers how they feel about it — Pipelines “working” and pipelines being a good use of expensive engineering talent are different statements. Ask the team — they will tell you where the waste is.
About the Author
Rajat Jindal is VP – Presales at AeonX Digital Technology Limited, where he architects winning cloud strategies for enterprise customers and translates modernization into measurable business value. He is a strong advocate of AWS, committed to sharing thought leadership that helps technology leaders make faster, better-informed decisions.
by Rajat Jindal | Apr 9, 2026 | AWS
The Uncomfortable Truth About Your Data Lake Investment
Between 2020 and 2024, enterprises invested billions in data lake initiatives. The promise was compelling: centralise all your data in Amazon S3, break down silos, enable analytics at scale. The technology delivered on that promise — S3 is the most durable, scalable, and cost-effective storage ever built.
But here is the uncomfortable truth I encounter in nearly every presales engagement: most enterprise data lakes are graveyards of good intentions. The data is there. Petabytes of it. Perfectly stored, perfectly durable, perfectly useless to AI.
The reason is structural. Data lakes were designed for a world where humans write SQL queries and know exactly what they are looking for. AI systems do not work that way. An AI agent does not know your table names. A Bedrock Knowledge Base cannot query a Parquet file by column name. A customer support copilot cannot search your data lake for “interactions similar to this complaint” — because similarity is a semantic concept, and your data lake speaks only in exact matches.
The gap between what your data lake stores and what AI can consume is the semantic gap. Closing it does not require rebuilding your data lake — it requires upgrading it with three capabilities that were never part of the original design: metadata that describes meaning, embeddings that encode similarity, and a discovery layer that lets AI systems find relevant data without human guidance.
This post is about that upgrade — and why the enterprises that close the semantic gap first will have a 12-18 month AI advantage over those still running SQL queries against data nobody remembers putting there.
Why Data Lakes Become Data Swamps: The Three Missing Properties
Every data swamp I have audited in presales discovery shares the same three structural failures. None of them are technology failures — they are design failures from an era before AI was a requirement.
A typical enterprise data lake contains thousands of objects in S3. Filenames like export_20240315_final_v2.csv and folder paths like raw/erp/batch_load_7/ tell you nothing about what the data actually represents.
For a human analyst who built the pipeline, this is navigable through tribal knowledge. For an AI system, it is opaque. A Bedrock agent asked “What were our top customer complaints last quarter?” cannot answer if it cannot discover that customer complaint data lives in s3://data-lake/raw/crm/zendesk_exports/ and that the relevant column is ticket_body, not description_text or notes_field.
The fix: AWS Glue Data Catalog provides the semantic metadata layer — table definitions, column descriptions, data types, and business glossary terms that make data discoverable by meaning, not just by path.
2. No Vector Representations — The “Find Similar Things” Problem
Traditional data lakes support one query pattern: exact match. WHERE customer_id = 12345 or WHERE region = 'APAC'. AI systems need a fundamentally different pattern: similarity search. “Find customer interactions similar to this complaint.” “Find documents related to this product issue.” “Find contracts with similar terms to this one.”
Similarity search requires vector embeddings — mathematical representations of meaning that can be compared using distance metrics. Your data lake has none of these. Every document, every interaction record, every knowledge article is stored in its raw form with no vector representation.
The fix: An embedding generation pipeline that converts your existing data lake content into vector representations stored alongside the source data — enabling semantic search without moving or duplicating the raw data.
3. No Discovery Layer — The “What Data Do We Even Have?” Problem
The most expensive question in enterprise AI is: “What data do we have that could answer this question?” In most organisations, the answer requires emailing three people, scheduling a meeting with the data engineering team, and waiting two weeks for a response.
AI agents cannot send emails. They need programmatic discovery — the ability to query a catalogue, understand what data exists, assess its relevance, and access it autonomously. Without this, every AI use case requires a custom integration built by a data engineer. That does not scale.
The fix: A combination of Glue Data Catalog (for structured discovery) and Bedrock Knowledge Bases (for semantic discovery) that lets AI systems self-serve data access based on meaning, not manual integration.
The Semantic Data Lake Architecture on AWS
The semantic data lake is not a replacement for your existing data lake. It is a layer on top — three upgrades that transform stored data into AI-consumable data without rebuilding what you already have.
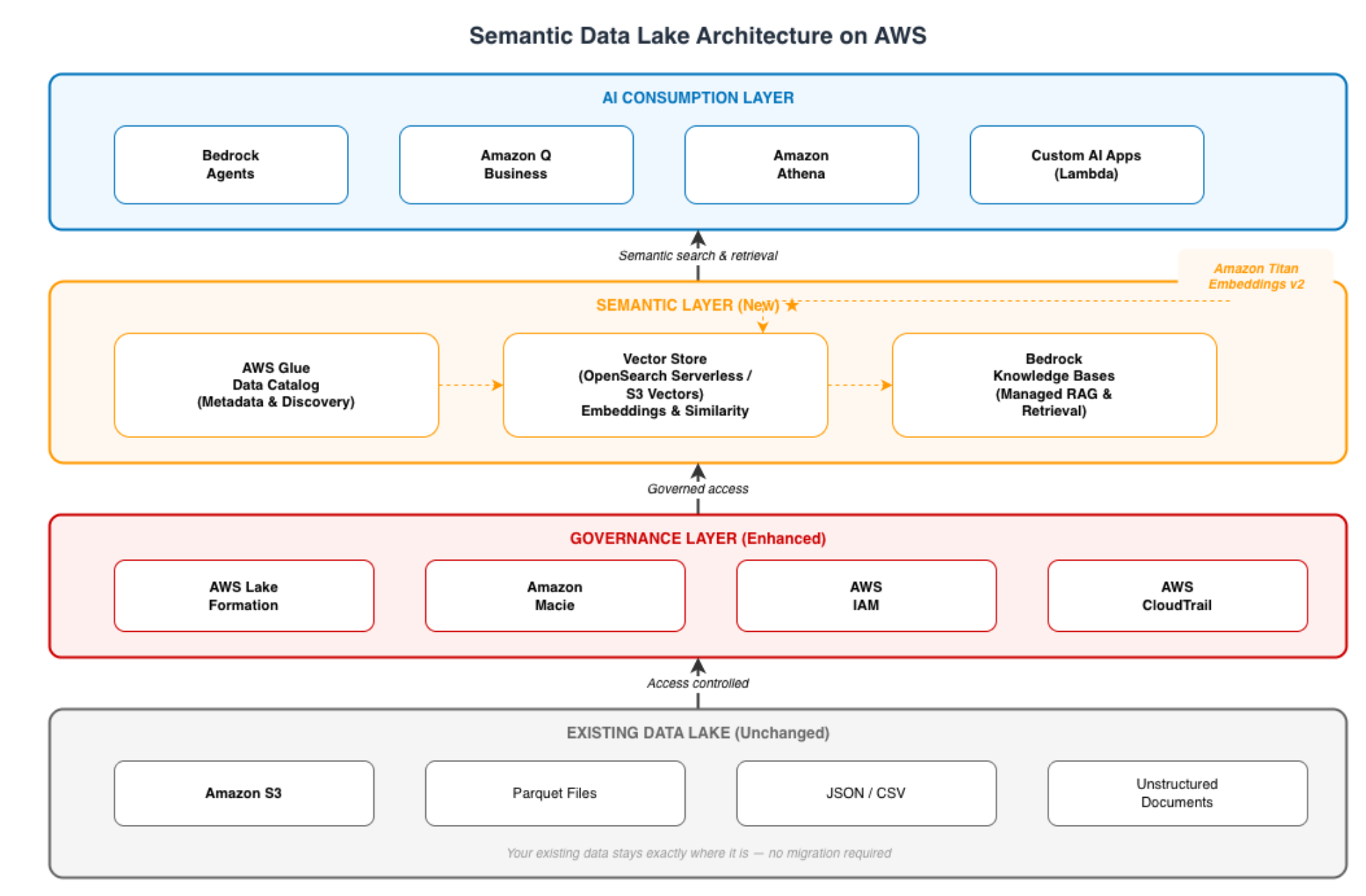
The critical design principle: your existing S3 data lake remains untouched. The semantic layer sits on top, indexing and embedding what is already there. No data migration. No pipeline rewrite. No disruption to existing analytics workloads.
The Glue Data Catalog is the first upgrade — it transforms your S3 storage from a file system into a discoverable knowledge repository.
Why This Matters for AI
Without a catalogue, an AI agent accessing your data lake is like a new employee on their first day with no onboarding — they can see the filing cabinets but have no idea what is in them or how to find anything relevant. The Glue Data Catalog provides the onboarding document.
Implementation Pattern
# Step 1: Create a database in the Glue Data Catalog
aws glue create-database \
--database-input '{
"Name": "crm_semantic_lake",
"Description": "Semantically catalogued CRM data for AI consumption. Contains customer interactions, support tickets, and engagement history.",
"Parameters": {
"data_owner": "customer-success-team",
"classification": "confidential",
"ai_ready": "true",
"last_catalogued": "2026-04-01"
}
}'
# Step 2: Run a Glue Crawler to auto-discover schema from S3
aws glue create-crawler \
--name crm-data-crawler \
--role arn:aws:iam::<account-id>:role/GlueCrawlerRole \
--database-name crm_semantic_lake \
--targets '{
"S3Targets": [
{"Path": "s3://enterprise-data-lake/crm/customer-interactions/"},
{"Path": "s3://enterprise-data-lake/crm/support-tickets/"},
{"Path": "s3://enterprise-data-lake/crm/engagement-history/"}
]
}' \
--schema-change-policy '{
"UpdateBehavior": "UPDATE_IN_DATABASE",
"DeleteBehavior": "LOG"
}'
# Step 3: Start the crawler — it discovers schema, data types, and partitions
aws glue start-crawler --name crm-data-crawler
The Business Value of Cataloguing
The crawler runs once and then on schedule (daily or weekly). After it completes, every table, column, and partition in your data lake is discoverable through a single API. But the real value is what you add on top — business descriptions that make the data meaningful to AI:
# Add semantic descriptions to discovered tables
import boto3
glue = boto3.client('glue', region_name='ap-south-1')
# Update table with business-meaningful metadata
glue.update_table(
DatabaseName='crm_semantic_lake',
TableInput={
'Name': 'customer_interactions',
'Description': 'All customer touchpoints including support tickets, sales calls, onboarding sessions, and escalations. Each record represents one interaction with timestamp, channel, resolution status, and full text content.',
'Parameters': {
'business_domain': 'customer-success',
'pii_contains': 'customer_name, email, phone',
'ai_embedding_status': 'pending',
'freshness_sla': 'daily',
'primary_use_cases': 'customer-insights-agent, support-copilot, churn-prediction'
}
}
)
The primary_use_cases parameter is the key AI-readiness pattern. When a Bedrock agent needs to answer “What complaints has this customer raised?”, the agent can query the catalogue to discover which table serves that use case — without a data engineer manually wiring the connection.
Building Block 2: The Embedding Pipeline — Making Data Semantically Searchable
Cataloguing tells AI what data exists. Embeddings tell AI what data means. This is the transformation that converts your data lake from “searchable by exact match” to “searchable by meaning.”
The Embedding Pipeline Pattern
# Glue ETL job: Generate embeddings for CRM interaction data
# Reads from the catalogued data lake, writes embeddings to vector store
import boto3
import json
from awsglue.context import GlueContext
from pyspark.context import SparkContext
sc = SparkContext()
glueContext = GlueContext(sc)
bedrock = boto3.client('bedrock-runtime', region_name='ap-south-1')
def generate_embedding(text: str) -> list:
"""Generate vector embedding using Amazon Titan Embeddings"""
response = bedrock.invoke_model(
modelId='amazon.titan-embed-text-v2:0',
contentType='application/json',
body=json.dumps({
"inputText": text,
"dimensions": 1024,
"normalize": True
})
)
result = json.loads(response['body'].read())
return result['embedding']
# Read from catalogued data lake
interactions = glueContext.create_dynamic_frame.from_catalog(
database="crm_semantic_lake",
table_name="customer_interactions"
)
# Convert to DataFrame for processing
df = interactions.toDF()
# Create searchable text by combining relevant fields
# This is the semantic content that AI will search against
df_with_text = df.withColumn(
"searchable_content",
concat_ws(" | ",
col("subject"),
col("body"),
col("resolution_notes"),
col("interaction_type")
)
)
# Generate embeddings (simplified — production would use batch processing)
# Write results to vector store for semantic search
Strategic Decision: Where to Store Vectors
| Option |
Best For |
Trade-off |
| Amazon OpenSearch Serverless |
Hybrid search (keyword + semantic), existing OpenSearch expertise |
Higher cost, more operational control |
| Bedrock Knowledge Bases |
Fastest time-to-value, fully managed, zero infrastructure |
Less customisation, managed chunking |
| S3 Vectors |
Massive scale (billions of vectors), cost-sensitive |
Newer service, less ecosystem tooling |
| Aurora pgvector |
Applications already on PostgreSQL |
Performance ceiling at very large scale |
My recommendation for most enterprises: Start with Bedrock Knowledge Bases. It handles chunking, embedding, indexing, and retrieval as a fully managed service. You point it at your S3 data, it does the rest. Move to OpenSearch or S3 Vectors only when you need custom retrieval logic or are operating at billions of vectors.
The reason: the fastest path to demonstrating AI value is the one with the fewest engineering dependencies. Bedrock Knowledge Bases removes the entire vector infrastructure question from your critical path.
Building Block 3: The AI Discovery Layer — Bedrock Knowledge Bases Over Your Data Lake
This is where the semantic data lake delivers business value. Bedrock Knowledge Bases connects directly to your S3 data lake, automatically chunks documents, generates embeddings, and provides a retrieval API that any AI application can query by meaning.
Configuration
{
"name": "enterprise-data-lake-kb",
"description": "Semantic search across enterprise data lake — CRM interactions, support knowledge base, product documentation",
"knowledgeBaseConfiguration": {
"type": "VECTOR",
"vectorKnowledgeBaseConfiguration": {
"embeddingModelArn": "arn:aws:bedrock:ap-south-1::foundation-model/amazon.titan-embed-text-v2:0"
}
},
"storageConfiguration": {
"type": "OPENSEARCH_SERVERLESS",
"opensearchServerlessConfiguration": {
"collectionArn": "arn:aws:aoss:ap-south-1:<account-id>:collection/<collection-id>",
"vectorIndexName": "data-lake-semantic-index",
"fieldMapping": {
"vectorField": "embedding",
"textField": "content",
"metadataField": "metadata"
}
}
},
"dataSourceConfiguration": {
"type": "S3",
"s3Configuration": {
"bucketArn": "arn:aws:s3:::enterprise-data-lake",
"inclusionPrefixes": [
"crm/customer-interactions/",
"knowledge-base/support-articles/",
"product/documentation/"
]
}
}
}
What This Enables
Before the semantic layer, answering “What similar issues have other customers experienced with our payment integration?” required:
- A data engineer to write a custom SQL query
- Knowledge of which tables contain payment-related data
- Manual text matching (LIKE ‘%payment%’) that misses semantic variants
- Hours of turnaround time
After the semantic layer, the same question is answered in seconds — the Bedrock Knowledge Base searches by meaning across all indexed content, retrieves semantically similar interactions regardless of exact keyword match, and returns grounded answers with source citations.
That difference — from hours of human effort to seconds of AI retrieval — is the ROI of the semantic data lake.
The semantic layer must respect the same access controls as the underlying data. This is non-negotiable for regulated industries — and it is the property that makes enterprise AI deployable rather than just demonstrable.
The Governance Challenge AI Creates
Traditional data lake governance controls who can run queries. AI governance must control what an AI system can see, return, and reference. These are different problems:
- A human analyst with access to HR data understands not to include salary information in a customer-facing report. An AI system will include it unless explicitly prevented.
- A human knows that draft financial data should not be cited as fact. An AI system treats all indexed data as equally authoritative.
- A human understands that a document marked “internal only” should not be summarised in an external communication. An AI system has no concept of audience.
# Grant the Bedrock Knowledge Base service role access ONLY to
# customer-facing data — not internal HR, finance, or legal content
aws lakeformation grant-permissions \
--principal '{
"DataLakePrincipalIdentifier": "arn:aws:iam::<account-id>:role/BedrockKnowledgeBaseRole"
}' \
--resource '{
"Table": {
"DatabaseName": "crm_semantic_lake",
"Name": "customer_interactions"
}
}' \
--permissions '["SELECT"]' \
--permissions-with-grant-option '[]'
# Explicitly DENY access to sensitive tables
aws lakeformation grant-permissions \
--principal '{
"DataLakePrincipalIdentifier": "arn:aws:iam::<account-id>:role/BedrockKnowledgeBaseRole"
}' \
--resource '{
"Table": {
"DatabaseName": "hr_data",
"Name": "employee_compensation"
}
}' \
--permissions '[]'
The principle: the AI service role gets the minimum access required for its use case. Customer-facing AI gets customer data. Internal productivity AI gets internal knowledge base content. No AI system gets unrestricted data lake access. This is the same least-privilege model that governs human access — applied to AI identities.
The Business Case: Semantic Upgrade vs Rebuild
The most common objection I hear: “We already spent $X million on our data lake. Now you want us to spend more?”
The answer is not “spend more.” The answer is “activate what you already paid for.”
Cost Comparison
| Approach |
Cost |
Timeline |
Risk |
| Rebuild data lake for AI from scratch |
$300K-$600K |
9-12 months |
High — disrupts existing analytics |
| Semantic layer upgrade (on top of existing) |
$50K-$120K |
6-10 weeks |
Low — existing workloads unchanged |
| Do nothing (build custom AI integrations per use case) |
$60K-$100K per use case |
4-8 weeks each |
Unsustainable — cost multiplies per use case |
The semantic upgrade pays for itself on the second AI use case. Every subsequent use case — customer insights agent, support copilot, knowledge search, compliance assistant — builds on the same semantic layer at near-zero marginal cost. The “custom integration per use case” approach costs $60K-$100K every time.
The 12-Month Value Timeline
| Month |
Milestone |
Business Value |
| 1-2 |
Catalogue + crawl existing data lake |
Discovery: “Here’s what data we actually have” |
| 3-4 |
First Knowledge Base on CRM data |
First AI use case live — customer insights agent |
| 5-6 |
Embedding pipeline for support articles |
Support copilot answers questions from your knowledge base |
| 7-8 |
Expand to product documentation + contracts |
Multi-domain semantic search |
| 9-12 |
Bedrock Agents autonomously querying the semantic lake |
Self-serve AI access — new use cases deploy in days, not months |
A Presales Perspective: Surfacing the Semantic Gap in Customer Conversations
The Discovery Question That Opens the Conversation
In every data & AI presales engagement, I ask one question early: “If I gave your AI team unlimited access to your data lake today, could they build a customer insights agent by Friday?”
The answer is always no. The follow-up question — “What’s missing?” — surfaces the semantic gap without me having to explain it. Customers self-identify the problems:
- “We don’t have good metadata — nobody knows what half the tables contain”
- “Our data is in raw format — AI can’t read Parquet files directly”
- “There’s no search — you have to know exactly what you’re looking for”
- “Governance would block it — we can’t give AI access to everything”
Each of those statements maps directly to a building block in the semantic data lake architecture. The customer has diagnosed themselves — I just need to show the solution.
The Framing That Resonates with CDOs and CTOs
“You already own the most valuable asset in AI — your proprietary enterprise data. It is sitting in S3, perfectly stored, perfectly durable. The only thing standing between that data and AI-powered business value is a semantic layer that makes it discoverable, searchable, and governed. That layer costs 5-10% of what you already invested in the lake — and it activates 100% of the value.”
That framing works because it positions the semantic layer as an activation investment, not a new initiative. Executives who approved the original data lake investment want to hear that their decision was correct — it just needs one more layer to deliver the AI value they are now being asked to demonstrate.
For CFOs: The Unit Economics
- Cost per AI use case without semantic layer: $60K-$100K (custom integration every time)
- Cost per AI use case with semantic layer: $10K-$20K (configuration + prompt engineering only)
- Break-even point: Second AI use case
- Year-one value (assuming 4-5 AI use cases): $180K-$350K in avoided custom engineering
Common Pitfalls: Lessons From Real Implementations
| Pitfall |
Consequence |
Prevention |
| Embedding everything without prioritisation |
$50K+ in unnecessary Titan Embeddings costs |
Start with highest-value data domains (CRM, support KB), expand based on demand |
| No freshness strategy |
AI answers based on stale data, user trust erodes |
EventBridge-triggered re-embedding on data updates, daily sync schedule minimum |
| Skipping governance |
AI surfaces confidential data in wrong context |
Lake Formation permissions BEFORE Knowledge Base indexing, not after |
| Choosing vector store before validating use case |
Over-engineering infrastructure |
Start with Bedrock Knowledge Bases (managed), migrate to self-hosted only when needed |
| No metadata standards |
Catalogue becomes as messy as the data lake |
Define naming conventions, required descriptions, and business glossary terms before crawling |
Why This Matters Now: The AI Advantage Window
The semantic data lake is not a permanent competitive advantage — it is a temporary one. Every enterprise will eventually upgrade their data lakes for AI. The question is who does it first.
The enterprises that close the semantic gap in 2026 will:
- Deploy AI use cases 4-5x faster than competitors still building custom integrations
- Compound their advantage as each new use case builds on the shared semantic layer
- Attract and retain AI talent who want to work on interesting problems — not spend months writing data pipeline glue code
The enterprises that wait will:
- Continue paying $80K-$150K per AI use case in custom engineering
- Watch competitors ship AI features monthly while they ship quarterly
- Eventually do the same upgrade, but under time pressure and at higher cost
The data lake investment was sound. The data is there. The semantic layer is the last mile that makes it useful to AI — and the organizations that build it first win the next 18 months.
Lessons for Technology Leaders
- Your data lake is not the problem — the missing semantic layer is — The storage investment was correct. The data is valuable. It just needs three properties (metadata, embeddings, discovery) to become AI-consumable.
- Catalogue first, embed second, govern always — The sequence matters. You cannot embed data you cannot find, and you cannot deploy AI over data you cannot govern. Glue Data Catalog → Embedding pipeline → Lake Formation → Bedrock Knowledge Bases.
- The semantic layer pays for itself on the second AI use case — Every use case after the first builds on the same infrastructure at marginal cost. The custom-integration-per-use-case approach does not have this property.
- Start with Bedrock Knowledge Bases, not custom vector infrastructure — The fastest path to proving value is the one with the fewest engineering dependencies. Prove the use case first, optimise the infrastructure second.
- The “data swamp” is a metadata problem, not a data problem — Your data is fine. Your metadata is missing. The Glue Crawler + business descriptions fix this in weeks, not months. The ROI of cataloguing is immediate — for AI and for human analysts.
About the Author
Rajat Jindal is VP – Presales at AeonX Digital Technology Limited, where he architects winning cloud strategies for enterprise customers and translates modernization into measurable business value. He is a strong advocate of AWS, committed to sharing thought leadership that helps technology leaders make faster, better-informed decisions.
by Rajat Jindal | Mar 26, 2026 | AWS
The Strategic Mistake Enterprises Are Making Right Now
In 90% of my presales conversations about AI, the first question from a CTO or VP Engineering is: “Which model should we use?” It is the wrong question — and answering it too early is the most expensive strategic mistake an enterprise can make in 2026.
The right question is: “How do we build an AI architecture that lets us use the best model for each task — and switch models without re-engineering when the market moves?”
The AI model landscape is evolving faster than any technology market in enterprise history. The model that was state-of-the-art six months ago is now mid-tier. The provider that was dominant in January may be third-choice by June. Any architecture that hardcodes a single model dependency is building in an expiration date — and that expiration date is measured in months, not years.
This post is about the architectural decisions that prevent model lock-in, the business case for a multi-model strategy, and how Amazon Bedrock makes this technically achievable without building a platform engineering team from scratch.
Why Single-Model Strategies Fail: Three Market Forces
In 2023, there was a clear performance hierarchy among foundation models. By late 2024, that hierarchy has become a rotation — different models lead on different tasks, and the gap between top-3 models on any given benchmark is often within statistical noise.
What this means for enterprise strategy: the “best model” changes depending on what you are asking it to do. A model that excels at structured data extraction may underperform on creative content generation. A model optimised for reasoning may be wastefully expensive for simple classification tasks. A single-model strategy forces you to use a premium model for every task — including the 60% of tasks where a smaller, cheaper model would deliver identical quality.
2. Pricing Pressure Is Restructuring the Economics
Foundation model pricing has dropped 80-90% in 18 months. But the price drops are not uniform — they favour organisations that can route traffic across multiple models based on task complexity. A single-model commitment means you cannot capitalise on pricing asymmetries that emerge monthly.
The concrete example: an enterprise running all AI workloads through a single large model at $15 per million input tokens could achieve identical output quality on 60-70% of those workloads using a model priced at $0.25-$3.00 per million input tokens. That is a 5-10x cost difference on the majority of production traffic — invisible to organisations locked into a single-model architecture.
3. Regulatory and Sovereignty Requirements Are Fragmenting
Data residency requirements, industry-specific regulations, and emerging AI governance frameworks are creating scenarios where different workloads must use different models — not by preference, but by mandate. A customer PII workload may require a model hosted in-region. An internal productivity workload may have no such constraint. A single-model strategy cannot accommodate this fragmentation without building separate infrastructure stacks.
What “Multi-Model” Actually Means: A Decision Framework
“Multi-model” is not “use every model available.” That creates chaos. It is a deliberate architectural strategy with three components:
Component 1: Task-to-Model Mapping
Every AI workload in your enterprise can be classified by complexity, latency requirement, and data sensitivity. Different classes of work should route to different models.
| Task Type |
Complexity |
Recommended Model Tier |
Example |
| Classification & routing |
Low |
Micro/Lite models |
Ticket categorisation, sentiment detection |
| Summarisation & extraction |
Medium |
Mid-tier models |
Document summarisation, data extraction |
| Complex reasoning & generation |
High |
Frontier models |
Architecture analysis, strategic content, multi-step planning |
| Code generation & debugging |
High |
Code-specialised models |
Application development, code review |
| Creative content |
Medium-High |
General-purpose large models |
Marketing copy, customer communications |
The strategic insight: most enterprise AI traffic is medium-complexity or below. Routing 60-70% of requests to appropriately-sized models — rather than sending everything to the most expensive frontier model — reduces AI infrastructure cost by 40-60% with no measurable quality degradation on those workloads.
Component 2: Model Evaluation as a Continuous Practice
Model selection is not a one-time decision. It is an ongoing operational practice — because models improve, new models launch, and your workload patterns evolve.
Amazon Bedrock Model Evaluation provides this capability as a managed service: run your actual production prompts against multiple models, score the outputs using LLM-as-a-judge evaluation, and make data-driven model selection decisions rather than relying on public benchmarks that may not represent your specific workload.
{
"evaluationConfig": {
"automated": {
"datasetMetricConfigs": [
{
"taskType": "Summarization",
"dataset": {
"name": "crm-summarization-test-set",
"datasetLocation": {
"s3Uri": "s3://ai-evaluation-data/test-sets/crm-summarization.jsonl"
}
},
"metricNames": [
"Accuracy",
"Completeness",
"Relevance"
]
}
]
}
},
"inferenceConfig": {
"models": [
{
"bedrockModel": {
"modelIdentifier": "anthropic.claude-3-5-sonnet-20241022-v2:0"
}
},
{
"bedrockModel": {
"modelIdentifier": "amazon.nova-pro-v1:0"
}
},
{
"bedrockModel": {
"modelIdentifier": "meta.llama3-1-70b-instruct-v1:0"
}
}
]
}
}
The practice this enables: quarterly model evaluation sprints where you test new models against your actual workloads and rebalance your routing decisions. This turns model selection from a political debate (“our team prefers Claude” vs “my developer likes Llama”) into a data-driven engineering practice with measurable outcomes.
Component 3: Abstraction Layer Architecture
The critical architectural decision: never let application code directly reference a specific model. Build an abstraction layer — a routing tier — that maps application requests to models. When you need to change models (and you will), you change the routing configuration, not the application code.
Amazon Bedrock provides this abstraction inherently. Every model is accessible through the same API contract (InvokeModel), the same authentication model (IAM), and the same governance layer (Guardrails). Switching from Claude to Nova to Llama requires changing a model identifier string — not rewriting your application.
This is the fundamental architectural advantage of a platform approach over direct API integration with individual model providers. Direct integration with a single provider’s API creates coupling at the application layer that makes future model migration a re-engineering project. Bedrock eliminates that coupling by design.
The Business Case: Multi-Model vs Single-Model Economics
Cost Comparison (Annual, 1,000-seat enterprise)
| Approach |
Model Cost |
Engineering Cost |
Total |
Risk |
| Single frontier model for all tasks |
$150K-$300K/year |
Low (one integration) |
$150K-$300K |
High lock-in, no pricing leverage |
| Multi-model with routing |
$60K-$120K/year |
Medium (routing layer) |
$80K-$140K |
Low lock-in, continuous optimisation |
| Estimated savings |
$90K-$180K/year |
— |
— |
— |
The savings come from three sources:
- Right-sizing: 60-70% of AI requests routed to appropriately-sized (cheaper) models
- Pricing leverage: ability to shift workloads to providers offering better pricing
- Innovation capture: ability to adopt better-performing models without migration cost
The Hidden Cost of Lock-In
Beyond direct model pricing, single-provider lock-in creates three hidden costs:
- Negotiation leverage: a customer committed to one provider has no leverage in pricing negotiations. A customer demonstrably running multiple models negotiates from strength.
- Innovation lag: when a better model launches from a competing provider, a locked-in customer faces a 3-6 month migration project before they can use it. A multi-model customer redirects traffic in hours.
- Talent retention: engineers want to work with the best tools. Locking into a single model provider signals architectural stagnation — the opposite of what retains strong engineering talent.
Implementation on Amazon Bedrock: The Multi-Model Architecture
Architecture Overview
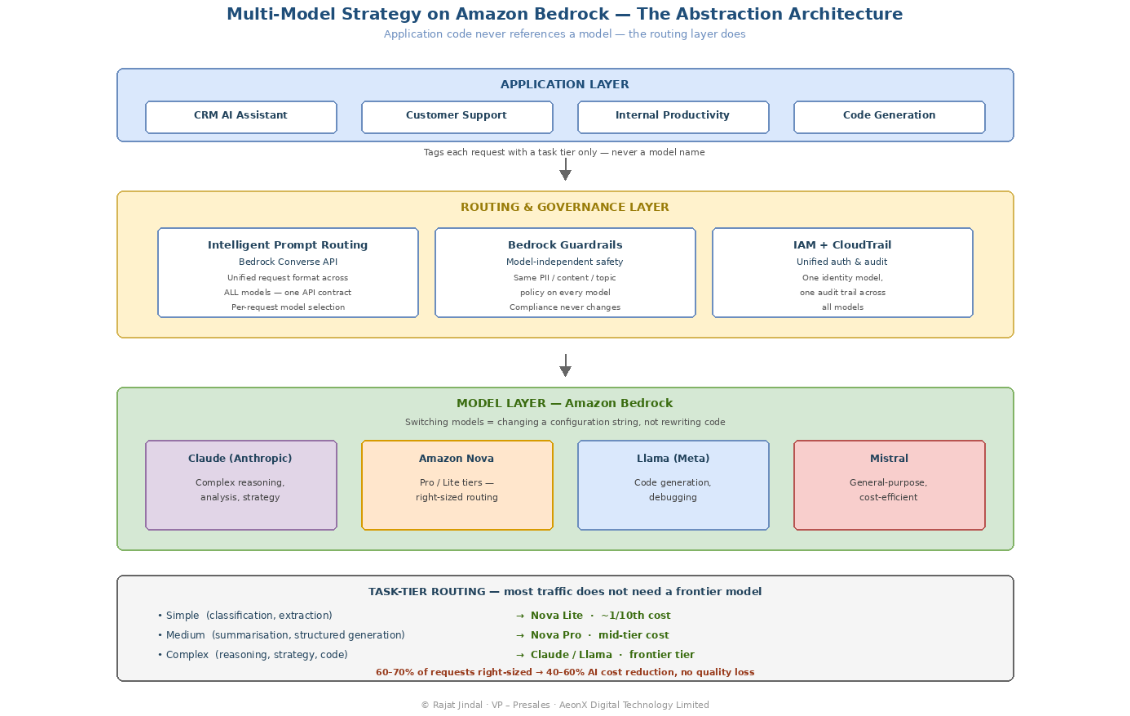
Building Block 1: Model Routing by Task Type
The simplest multi-model pattern routes requests based on declared task type. Your application tags each request with its complexity tier, and the routing layer selects the appropriate model.
import boto3
import json
bedrock_runtime = boto3.client('bedrock-runtime', region_name='ap-south-1')
# Model routing configuration — change here, not in application code
MODEL_ROUTING = {
"simple": "amazon.nova-lite-v1:0", # Classification, extraction, simple Q&A
"medium": "amazon.nova-pro-v1:0", # Summarisation, structured generation
"complex": "anthropic.claude-3-5-sonnet-20241022-v2:0", # Reasoning, analysis, strategy
"code": "meta.llama3-1-70b-instruct-v1:0" # Code generation, debugging
}
def invoke_model(prompt: str, task_tier: str, max_tokens: int = 1024):
"""
Route AI requests to the appropriate model based on task complexity.
Application code never references a specific model — only a task tier.
"""
model_id = MODEL_ROUTING.get(task_tier, MODEL_ROUTING["medium"])
# Unified request format — works across all Bedrock models
response = bedrock_runtime.invoke_model(
modelId=model_id,
contentType="application/json",
accept="application/json",
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31" if "anthropic" in model_id else None,
"messages": [{"role": "user", "content": prompt}],
"max_tokens": max_tokens
})
)
return json.loads(response['body'].read())
# Example usage — application code is model-agnostic
result = invoke_model(
prompt="Categorise this support ticket: 'Cannot login to portal'",
task_tier="simple" # Routes to Nova Lite — fast, cheap, sufficient
)
result = invoke_model(
prompt="Analyse the architectural trade-offs between ECS and EKS for this workload...",
task_tier="complex" # Routes to Claude 3.5 Sonnet — maximum reasoning quality
)
The critical design decision: when you discover a better model for a task tier — or when pricing changes make a different model more attractive — you update the MODEL_ROUTING dictionary. Zero application code changes. Zero redeployment of downstream services. This is the architectural property that eliminates lock-in.
Building Block 2: Intelligent Prompt Routing (Preview)
Amazon Bedrock Intelligent Prompt Routing takes this further — it automatically routes prompts to different models within a model family based on the complexity of each individual prompt, without requiring you to manually classify task tiers.
Announced at re:Invent 2024 and available in preview, Intelligent Prompt Routing dynamically predicts the response quality of each model for a given request and routes accordingly. Simple prompts go to smaller, faster, cheaper models. Complex prompts go to larger, more capable models. The routing decision happens per-request, in real-time, with no application code changes.
The business impact: AWS states this can reduce costs by up to 30% without compromising accuracy — because the majority of prompts in any production workload do not require frontier-model reasoning.
Building Block 3: Guardrails Across All Models
A critical governance requirement for multi-model architectures: your safety controls must apply uniformly regardless of which model processes the request. Amazon Bedrock Guardrails provides this — a single guardrail configuration enforced across every model in your routing tier.
{
"name": "enterprise-ai-guardrail",
"description": "Applied to ALL models regardless of routing decision",
"contentPolicyConfig": {
"filtersConfig": [
{"type": "HATE", "inputStrength": "HIGH", "outputStrength": "HIGH"},
{"type": "VIOLENCE", "inputStrength": "HIGH", "outputStrength": "HIGH"},
{"type": "SEXUAL", "inputStrength": "HIGH", "outputStrength": "HIGH"},
{"type": "MISCONDUCT", "inputStrength": "HIGH", "outputStrength": "HIGH"}
]
},
"sensitiveInformationPolicyConfig": {
"piiEntitiesConfig": [
{"type": "EMAIL", "action": "ANONYMIZE"},
{"type": "PHONE", "action": "ANONYMIZE"},
{"type": "CREDIT_DEBIT_CARD_NUMBER", "action": "BLOCK"}
]
},
"topicPolicyConfig": {
"topicsConfig": [
{
"name": "competitor-discussion",
"definition": "Questions about or comparisons with specific competitor products",
"type": "DENY"
}
]
}
}
This guardrail applies identically whether the request is routed to Claude, Nova, Llama, or Mistral. The governance layer is model-independent — which means your compliance posture does not change when you change models. For regulated industries, this property is non-negotiable: you cannot have different safety guarantees depending on which model happens to process a request.
Building Block 4: Cross-Region Inference for Resilience
A multi-model architecture inherently provides resilience that a single-model architecture cannot. But Amazon Bedrock adds another layer: cross-region inference automatically distributes traffic across regions during peak demand, providing up to 2x throughput without any application changes.
For enterprises with data residency requirements, cross-region inference can be configured with geographic boundaries — ensuring that inference processing stays within approved jurisdictions while still benefiting from multi-region resilience.
A Presales Perspective: How to Position Multi-Model Strategy in Customer Conversations
The Conversation Pattern That Works
In my experience, the multi-model conversation resonates most strongly when framed not as a technical architecture decision, but as a procurement and negotiation strategy.
Step 1 — Surface the hidden lock-in
Most enterprises do not realise they are locked in until they try to move. The question I ask: “If your primary AI model provider raised prices by 50% tomorrow, how long would it take you to switch to an alternative?” If the answer is “months” or “we’d have to rewrite our application,” they are locked in. That recognition is the opening.
Step 2 — Show the economics
Walk through the task-tier analysis: what percentage of their AI traffic actually requires frontier-model reasoning? In every enterprise I have analysed, the answer is 20-40%. The remaining 60-80% is classification, extraction, simple summarisation — tasks where a model at 1/10th the price delivers equivalent quality. That gap is their multi-model savings opportunity.
Step 3 — Demonstrate the Bedrock advantage
The reason Amazon Bedrock wins this conversation is simple: it is the only platform that provides Claude, Nova, Llama, and Mistral through a single API, single governance layer, and single billing relationship. The alternative — integrating directly with each provider’s API — creates the exact multi-vendor management complexity that enterprises are trying to avoid.
The Objections You Will Hear
“We’re already standardised on [Provider X]”
Response: “That’s fine for today’s workload. But which model will be best for your workload in 12 months? If it’s a different provider, how much does switching cost? Bedrock lets you keep using [Provider X] today while maintaining the architectural option to switch tomorrow — at zero additional cost.”
“Multi-model adds complexity”
Response: “Direct multi-provider integration adds complexity. A platform that abstracts model selection behind a unified API removes complexity. You write to one API. The routing is configuration, not code.”
“Our developers prefer [Model Y]”
Response: “Developer preference is valid for development and experimentation. Production model selection should be based on evaluation data — cost, quality, latency — not preference. Bedrock Model Evaluation gives you that data. Often, the model developers prefer for interactive use is not the most cost-effective for production batch workloads.”
The Model Lock-In Test: Five Questions for Technology Leaders
Ask your team these five questions. If more than two answers are “yes,” you have a lock-in problem:
- Does your application code directly reference a specific model provider’s API? (Not Bedrock’s unified API — the provider’s own SDK/endpoint)
- Would changing AI models require code changes in more than one service?
- Do you have a single AI vendor whose pricing increase would directly impact your P&L with no short-term alternative?
- Is your AI cost per transaction increasing quarter-over-quarter despite traffic being stable? (You are paying frontier prices for non-frontier tasks)
- Has your team evaluated an alternative model in the last 90 days? (If no, you have lock-in by inertia, not by choice)
If your score is 3+ “yes” answers, the multi-model conversation is urgent — not because your current model is bad, but because your current architecture is fragile.
Why This Matters Now: The 12-Month Forecast
Three developments will make multi-model strategy mandatory — not optional — within the next 12 months:
- Model specialisation is accelerating — general-purpose models are being joined by task-specific models (code, reasoning, vision, structured data) that dramatically outperform generalists on their target task. A single-model strategy cannot access these specialists.
- Pricing competition will intensify — as more providers reach production quality, pricing will compress further. Enterprises with multi-model flexibility will capture these savings automatically. Locked-in enterprises will watch from the sidelines.
- Regulatory requirements will fragment model choice — emerging AI governance frameworks in the EU, India, and other jurisdictions will create scenarios where specific data types must be processed by models meeting specific residency or certification requirements. A single-model architecture cannot accommodate this without parallel infrastructure.
The enterprises that build multi-model architecture now will have 12 months of operational experience, evaluation data, and cost optimisation when these forces arrive. The enterprises that wait will face a combined migration-and-compliance project under time pressure. Which position would you rather be in?
Lessons for Technology Leaders
- “Which model should we use?” is the wrong first question — The right question is “How do we build an architecture that lets us use the best model for each task and change models without re-engineering?” Answer that first, and the model selection question becomes a configuration decision, not an architecture decision.
- Multi-model is a cost strategy, not just a risk strategy — The immediate savings from right-sizing models to tasks (40-60% cost reduction on AI workloads) pays for the architectural investment in months, not years. This is not theoretical — it is arithmetic.
- Amazon Bedrock is not an AI service — it is an AI platform strategy — The value of Bedrock is not any single model. It is the unified API, governance, and billing that makes model switching a configuration change. That architectural property is worth more than any individual model capability.
- Model evaluation should be a quarterly practice, not a one-time decision — The model landscape changes every quarter. If you are not re-evaluating, you are overpaying — either in cost (using an expensive model where a cheaper one suffices) or in quality (using last quarter’s best when this quarter’s best is available).
- The CTO who says “we’re a Claude shop” or “we’re a Llama shop” is making a procurement statement, not an architecture statement — In 12 months, that statement will be as outdated as “we’re an Oracle shop” is today. Build for flexibility.
About the Author
Rajat Jindal is VP – Presales at AeonX Digital Technology Limited, where he architects winning cloud strategies for enterprise customers and translates modernization into measurable business value. He is a strong advocate of AWS, committed to sharing thought leadership that helps technology leaders make faster, better-informed decisions.
by Rajat Jindal | Mar 5, 2026 | AWS
While your security team is monitoring network perimeters and patching vulnerabilities, your employees are sharing customer data, source code, and board presentations with public AI tools every day. This is not a future risk. It is a present one.
Introduction
“Last quarter, I was in a security review with a CISO who had just completed a comprehensive third-party risk assessment. Fourteen vendors assessed, every integration documented, every data flow mapped. I asked one question that wasn’t on the agenda: how many AI tools are your employees using that aren’t on that list? She paused. Then she said ‘three, maybe four.’ We ran a basic discovery exercise using AWS CloudTrail and DNS query logs. The actual number was nineteen. Fourteen of them had been in active use for more than six months. Every one of them was a potential data exfiltration channel that had never appeared on a risk register. That is the Shadow AI problem.”
1. The Shadow AI Problem Nobody Wants to Name
Enterprises have spent a decade managing Shadow IT — employees using unauthorised SaaS tools that IT hadn’t approved. That battle was difficult but manageable. Shadow AI is the same problem at ten times the velocity and a hundred times the data sensitivity.
The scale is not theoretical. Right now, in your organisation, employees are using public AI tools for:
- Drafting emails and proposals that contain customer names, deal values, and competitive intelligence
- Summarising board presentations and strategy documents
- Debugging and generating code that contains proprietary algorithms, API keys, and internal architecture details
- Translating contracts and legal documents that contain confidential commercial terms
- Analysing financial models and forecasts that constitute material non-public information in listed companies
The uncomfortable truth: every one of these use cases involves an employee sharing confidential enterprise data with a third-party AI model that processes — and in some cases retains — that input. The data leaves the building. In most cases, it leaves permanently.
The framing that resonates with CISOs: Shadow AI is not a policy violation problem. It is a data sovereignty problem. And unlike traditional Shadow IT, the damage is not recoverable — you cannot un-share data with a language model.
2. Why Shadow AI Is Categorically Different from Shadow IT
Shadow IT created unauthorised systems. Shadow AI creates unauthorised data flows. That distinction matters enormously from a risk and governance perspective, and it rests on three structural differences.
When an employee uses an unauthorised SaaS project management tool, the data sits in that tool’s database — visible, retrievable, potentially deletable under a data subject request. When an employee pastes a customer contract into a public AI assistant, that data is processed by a model, potentially logged, and potentially used for training. There is no “retrieve and delete.” The exposure is permanent the moment the prompt is submitted.
The use case is almost always legitimate
Shadow IT often involved employees circumventing IT for convenience. Shadow AI involves employees trying to do their jobs faster and better. They are not doing anything wrong by their own reasoning — they are using the best available tool for the task in front of them. This makes restriction both ethically harder to justify and practically less effective to enforce.
The velocity is impossible to match with traditional governance
IT approval processes for new tools take weeks or months. A new AI tool can be discovered, signed up for, and used in five minutes. By the time your governance process has evaluated one tool, half your organisation has already adopted it — and a quarter has abandoned it for the next one.
The Presales reframe: in security conversations, I reframe Shadow AI from a compliance problem to a competitive intelligence problem. The question is not “are your employees breaking policy?” It is “is your product roadmap, customer data, and financial strategy being fed into AI models operated by companies whose interests are not aligned with yours?” That version of the question gets executive attention.
3. The Real Risk Inventory: What Data Is Actually Leaving Your Organisation
Abstract risk discussions don’t move budgets. Concrete data categories do. This is what is actually being shared with public AI tools in a typical enterprise, and what each category exposes:
| Data Category |
Common Shadow AI Use Case |
Risk Classification |
| Customer data |
Summarising CRM notes, drafting personalised proposals |
GDPR / DPDP Act violation, contractual breach |
| Source code |
Debugging, code completion, architecture review |
IP exposure, competitive intelligence, licence violation |
| Financial forecasts |
Analysing variance, drafting board commentary |
Market-sensitive information, insider trading risk |
| M&A documents |
Summarising term sheets, drafting due diligence notes |
Material non-public information, deal confidentiality breach |
| HR and employee data |
Drafting performance reviews, summarising surveys |
Employment law exposure, GDPR special category data |
| Legal contracts |
Summarising terms, translating agreements |
Privilege waiver risk, confidentiality breach |
| Strategy documents |
Summarising roadmaps, drafting presentations |
Competitive intelligence exposure |
The point worth making explicitly: no employee sharing data in these categories intends to create a security incident. They are trying to work faster. The risk is structural — the tool, not the behaviour, creates the exposure. Which means the solution must be structural too: provide a governed AI that is better than the ungoverned alternative, rather than trying to police the behaviour.
4. Why Traditional IT Governance Fails for AI
Traditional IT governance was designed for a world where new tools are discrete, visible, and slow to adopt. AI tools are ubiquitous, invisible in network traffic, and adopted in minutes. Three specific governance failures follow.
- Approval velocity mismatch — The average enterprise IT tool approval process takes 6–12 weeks. The average AI tool adoption cycle — from an employee discovering a tool to organisation-wide use — is 2–4 weeks. Governance is structurally behind before it starts.
- Visibility gap — AI tools are accessed via HTTPS to generic cloud domains. Traditional DLP and network monitoring cannot reliably distinguish “employee browsing the web” from “employee submitting confidential documents to an AI tool.” The data leaves without triggering any existing control.
- The Streisand Effect of banning — In every organisation where I have seen AI tools banned outright, usage went underground rather than stopping. Employees switch to personal devices, personal accounts, and mobile networks. Governance visibility drops from low to zero. Banning AI tools does not reduce the risk — it eliminates your sight of it.
The conclusion: the only governance model that works for Shadow AI is one that removes the incentive to use ungoverned tools. That means providing governed AI that is genuinely better than the alternative — not merely permitted, but preferred.
5. The AWS Framework: Governed AI as the Replacement Strategy
The reason employees use public AI tools is not that they are rebellious — it is that those tools are genuinely useful. The way to win the Shadow AI battle is not restriction but replacement: provide governed AI that beats the ungoverned alternative on usefulness, not just on compliance.
And there is one argument that wins this comparison every time: Amazon Q Business can do something public AI tools fundamentally cannot. It can answer questions about your specific company’s data. When an employee asks “what did we quote to that customer last quarter?”, a public AI tool cannot answer — it has no access to your CRM. Amazon Q Business, connected to Salesforce, SharePoint, and Confluence with IAM-scoped access, answers it in seconds.
The governed AI platform has three components:
- Amazon Q Business — the employee-facing governed AI assistant, connected to corporate data sources, respecting existing permissions, with full audit trails
- Amazon Bedrock — the foundation model platform for custom AI applications built by your technology teams, with model choice and data isolation guarantees
- AWS IAM Identity Center + Bedrock Guardrails — the governance layer that enforces access controls, content policies, and auditability across both
Three technical building blocks take this from strategy to implementation. Each is deployable independently; together they form the complete governed AI platform.
Building block 1: Detect Shadow AI with CloudTrail and Athena
Before you can replace Shadow AI, you need to see it. This Athena query surfaces AI tool usage patterns from your network logs — run it against your existing CloudTrail and DNS query logs to establish the baseline:
-- Athena query: detect Shadow AI tool usage from DNS query logs
-- (Route 53 Resolver query logging to S3)
SELECT
query_name,
srcaddr AS source_ip,
COUNT(*) AS query_count,
COUNT(DISTINCT srcaddr) AS unique_sources,
MIN(query_timestamp) AS first_seen,
MAX(query_timestamp) AS last_seen
FROM dns_resolver_logs
WHERE (
query_name LIKE '%openai.com%'
OR query_name LIKE '%chatgpt.com%'
OR query_name LIKE '%claude.ai%'
OR query_name LIKE '%gemini.google.com%'
OR query_name LIKE '%copilot.microsoft.com%'
OR query_name LIKE '%perplexity.ai%'
)
AND from_iso8601_timestamp(query_timestamp)
> current_timestamp - INTERVAL '30' DAY
GROUP BY query_name, srcaddr
ORDER BY query_count DESC;
Combine Route 53 Resolver DNS logs with VPC Flow Logs for comprehensive coverage — DNS logging captures every outbound AI tool connection regardless of how the user authenticated. The output of this query is your Shadow AI baseline: which tools, which business units, what volume. That number is the opening slide of your CISO conversation.
Building block 2: Deploy Amazon Q Business with permission-scoped data access
Amazon Q Business inherits each user’s existing data permissions — it cannot surface a document to a user who couldn’t open it manually. This is the property that makes governed AI deployable in regulated environments:
{
"applicationName": "enterprise-governed-ai",
"identityCenterInstanceArn": "arn:aws:sso:::instance/<instance-id>",
"roleArn": "arn:aws:iam::<account-id>:role/QBusinessServiceRole",
"attachmentsConfiguration": {
"attachmentsControlMode": "ENABLED"
},
"dataSources": [
{
"displayName": "SharePoint-Internal",
"connectorType": "SHAREPOINT",
"configuration": {
"connectionConfiguration": {
"repositoryEndpointMetadata": {
"siteUrls": ["https://<tenant>.sharepoint.com/sites/internal"]
}
},
"aclConfiguration": {
"crawlAcl": true
}
}
}
]
}
The aclConfiguration with crawlAcl set to true is the critical line: Q Business indexes each document’s access control list alongside its content, so query responses are filtered per-user at retrieval time. The CISO question “can the AI leak documents across permission boundaries?” has a technical answer: no, by design.
Building block 3: Enforce AI usage boundaries with an Organizations SCP
A Service Control Policy at the AWS Organizations level ensures all Bedrock workloads stay within approved regions — keeping AI data processing inside your regulatory boundary:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "RestrictBedrockToApprovedRegions",
"Effect": "Deny",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream",
"bedrock:CreateKnowledgeBase",
"bedrock:CreateAgent"
],
"Resource": "*",
"Condition": {
"StringNotEquals": {
"aws:RequestedRegion": [
"ap-south-1",
"us-east-1"
]
}
}
}
]
}
This SCP prevents any account in the organisation from invoking Bedrock models or creating AI resources outside the approved regions — ap-south-1 for data residency-sensitive workloads, us-east-1 for everything else. Pair it with a data classification policy that maps approved regions to data sensitivity levels, and AI region compliance becomes automatic rather than audited.
7. A Presales Perspective: How to Have This Conversation With Your CISO
The Shadow AI conversation fails when it is framed as a threat. CISOs hear about new threats every day. What gets budget is a threat with a measurable scale and a practical solution. The three-step conversation that works:
Step 1 — Establish the scale with data, not anecdote
Start with a discovery sprint: two weeks, CloudTrail plus DNS logs, no policy changes, no announcements. Then show the CISO a real number — not “employees might be using AI tools” but “your organisation made 847 connections to external AI services last month, from these business units, in these patterns.” Numbers generated by your own infrastructure are impossible to dismiss.
Step 2 — Reframe from compliance to competitive risk
CISOs are desensitised to compliance arguments. The question that lands differently: “If a competitor had access to the last six months of AI queries your employees submitted to public tools, what would they know about your strategy, your customers, and your product roadmap?” That question reframes Shadow AI from an IT governance failure into a competitive intelligence exposure — and that is a board-level concern.
Step 3 — Lead with the replacement, not the restriction
The moment you propose banning AI tools, you lose the business stakeholders in the room — they are the ones using the tools. Lead instead with what Amazon Q Business can do that public AI cannot: answer questions grounded in internal data. Demonstrate it answering a question about the company’s own documents. The restriction conversation becomes unnecessary once employees have a better alternative — adoption does the enforcement for you.
8. The Business Case: Governed AI vs Ungoverned Shadow AI
Frame the decision as a cost comparison that the CISO and CFO can act on together.
The cost of doing nothing (annual exposure, mid-market enterprise)
- Regulatory exposure — a single GDPR breach involving AI data sharing averages €85K–€250K in fines plus remediation effort
- Incident response — the average AI-related security incident costs roughly $180K in investigation, containment, and remediation
- IP exposure — unquantifiable but material: a leaked product roadmap, a shared proprietary algorithm, a disclosed customer list cannot be recalled
- Audit findings — AI governance gaps now appear in ISO 27001 and SOC 2 audits; each finding costs weeks of remediation and delays customer security reviews
- Amazon Q Business licensing — approximately $20 per user per month; ~$240K per year for 1,000 users
- Implementation — 4–6 weeks for initial deployment with 2–3 data source connectors
- Ongoing governance — runs on your existing IAM model and existing CloudTrail; no new security tooling required
The CFO argument: governed AI is not an AI investment. It is a risk mitigation investment with an AI productivity benefit included at no extra charge. Framed that way, it competes for security budget — which exists — rather than innovation budget, which is always contested.
9. Lessons for Technology Leaders
- Shadow AI is not a future risk — audit it this quarter. Two weeks with CloudTrail and DNS logs will show you the real number. The number will surprise you.
- Banning AI tools does not reduce Shadow AI risk — it eliminates your visibility into it. Employees will find a way. Give them a better way that you can see.
- Amazon Q Business wins the replacement argument because it does what public AI cannot — answer questions about your company’s specific data. That is the feature that drives voluntary adoption of the governed alternative.
- Govern the identity, not the tool. AWS IAM Identity Center applied to AI services means governed AI inherits existing permissions — the same model that already governs every other enterprise system.
- Make the CISO and CFO co-sponsors. Shadow AI is a risk conversation and a cost conversation simultaneously. The business case closes fastest when both are in the room.
Conclusion
“The Shadow AI battle will not be won by policy. It will not be won by monitoring. It will be won by the organisation that provides AI so genuinely useful — with access to real company data, with a trust model that matches existing permissions, with audit trails that satisfy the regulator — that employees stop looking for the ungoverned alternative. Amazon Q Business is not the answer to Shadow AI because it is more secure than public AI tools. It is the answer because it is more useful. That is the only argument that has ever won a Shadow IT battle.”
About the Author
Rajat Jindal is VP – Presales at AeonX Digital Technology Limited, where he architects winning cloud strategies for enterprise customers and translates modernization into measurable business value. He is a strong advocate of AWS, committed to sharing thought leadership that helps technology leaders make faster, better-informed decisions.