The Strategic Mistake Enterprises Are Making Right Now
In 90% of my presales conversations about AI, the first question from a CTO or VP Engineering is: “Which model should we use?” It is the wrong question — and answering it too early is the most expensive strategic mistake an enterprise can make in 2026.
The right question is: “How do we build an AI architecture that lets us use the best model for each task — and switch models without re-engineering when the market moves?”
The AI model landscape is evolving faster than any technology market in enterprise history. The model that was state-of-the-art six months ago is now mid-tier. The provider that was dominant in January may be third-choice by June. Any architecture that hardcodes a single model dependency is building in an expiration date — and that expiration date is measured in months, not years.
This post is about the architectural decisions that prevent model lock-in, the business case for a multi-model strategy, and how Amazon Bedrock makes this technically achievable without building a platform engineering team from scratch.
Why Single-Model Strategies Fail: Three Market Forces
1. The Performance Gap Is Collapsing
In 2023, there was a clear performance hierarchy among foundation models. By late 2024, that hierarchy has become a rotation — different models lead on different tasks, and the gap between top-3 models on any given benchmark is often within statistical noise.
What this means for enterprise strategy: the “best model” changes depending on what you are asking it to do. A model that excels at structured data extraction may underperform on creative content generation. A model optimised for reasoning may be wastefully expensive for simple classification tasks. A single-model strategy forces you to use a premium model for every task — including the 60% of tasks where a smaller, cheaper model would deliver identical quality.
2. Pricing Pressure Is Restructuring the Economics
Foundation model pricing has dropped 80-90% in 18 months. But the price drops are not uniform — they favour organisations that can route traffic across multiple models based on task complexity. A single-model commitment means you cannot capitalise on pricing asymmetries that emerge monthly.
The concrete example: an enterprise running all AI workloads through a single large model at $15 per million input tokens could achieve identical output quality on 60-70% of those workloads using a model priced at $0.25-$3.00 per million input tokens. That is a 5-10x cost difference on the majority of production traffic — invisible to organisations locked into a single-model architecture.
3. Regulatory and Sovereignty Requirements Are Fragmenting
Data residency requirements, industry-specific regulations, and emerging AI governance frameworks are creating scenarios where different workloads must use different models — not by preference, but by mandate. A customer PII workload may require a model hosted in-region. An internal productivity workload may have no such constraint. A single-model strategy cannot accommodate this fragmentation without building separate infrastructure stacks.
What “Multi-Model” Actually Means: A Decision Framework
“Multi-model” is not “use every model available.” That creates chaos. It is a deliberate architectural strategy with three components:
Component 1: Task-to-Model Mapping
Every AI workload in your enterprise can be classified by complexity, latency requirement, and data sensitivity. Different classes of work should route to different models.
| Task Type | Complexity | Recommended Model Tier | Example |
|---|---|---|---|
| Classification & routing | Low | Micro/Lite models | Ticket categorisation, sentiment detection |
| Summarisation & extraction | Medium | Mid-tier models | Document summarisation, data extraction |
| Complex reasoning & generation | High | Frontier models | Architecture analysis, strategic content, multi-step planning |
| Code generation & debugging | High | Code-specialised models | Application development, code review |
| Creative content | Medium-High | General-purpose large models | Marketing copy, customer communications |
The strategic insight: most enterprise AI traffic is medium-complexity or below. Routing 60-70% of requests to appropriately-sized models — rather than sending everything to the most expensive frontier model — reduces AI infrastructure cost by 40-60% with no measurable quality degradation on those workloads.
Component 2: Model Evaluation as a Continuous Practice
Model selection is not a one-time decision. It is an ongoing operational practice — because models improve, new models launch, and your workload patterns evolve.
Amazon Bedrock Model Evaluation provides this capability as a managed service: run your actual production prompts against multiple models, score the outputs using LLM-as-a-judge evaluation, and make data-driven model selection decisions rather than relying on public benchmarks that may not represent your specific workload.
{
"evaluationConfig": {
"automated": {
"datasetMetricConfigs": [
{
"taskType": "Summarization",
"dataset": {
"name": "crm-summarization-test-set",
"datasetLocation": {
"s3Uri": "s3://ai-evaluation-data/test-sets/crm-summarization.jsonl"
}
},
"metricNames": [
"Accuracy",
"Completeness",
"Relevance"
]
}
]
}
},
"inferenceConfig": {
"models": [
{
"bedrockModel": {
"modelIdentifier": "anthropic.claude-3-5-sonnet-20241022-v2:0"
}
},
{
"bedrockModel": {
"modelIdentifier": "amazon.nova-pro-v1:0"
}
},
{
"bedrockModel": {
"modelIdentifier": "meta.llama3-1-70b-instruct-v1:0"
}
}
]
}
}The practice this enables: quarterly model evaluation sprints where you test new models against your actual workloads and rebalance your routing decisions. This turns model selection from a political debate (“our team prefers Claude” vs “my developer likes Llama”) into a data-driven engineering practice with measurable outcomes.
Component 3: Abstraction Layer Architecture
The critical architectural decision: never let application code directly reference a specific model. Build an abstraction layer — a routing tier — that maps application requests to models. When you need to change models (and you will), you change the routing configuration, not the application code.
Amazon Bedrock provides this abstraction inherently. Every model is accessible through the same API contract (InvokeModel), the same authentication model (IAM), and the same governance layer (Guardrails). Switching from Claude to Nova to Llama requires changing a model identifier string — not rewriting your application.
This is the fundamental architectural advantage of a platform approach over direct API integration with individual model providers. Direct integration with a single provider’s API creates coupling at the application layer that makes future model migration a re-engineering project. Bedrock eliminates that coupling by design.
The Business Case: Multi-Model vs Single-Model Economics
Cost Comparison (Annual, 1,000-seat enterprise)
| Approach | Model Cost | Engineering Cost | Total | Risk |
|---|---|---|---|---|
| Single frontier model for all tasks | $150K-$300K/year | Low (one integration) | $150K-$300K | High lock-in, no pricing leverage |
| Multi-model with routing | $60K-$120K/year | Medium (routing layer) | $80K-$140K | Low lock-in, continuous optimisation |
| Estimated savings | $90K-$180K/year | — | — | — |
The savings come from three sources:
- Right-sizing: 60-70% of AI requests routed to appropriately-sized (cheaper) models
- Pricing leverage: ability to shift workloads to providers offering better pricing
- Innovation capture: ability to adopt better-performing models without migration cost
The Hidden Cost of Lock-In
Beyond direct model pricing, single-provider lock-in creates three hidden costs:
- Negotiation leverage: a customer committed to one provider has no leverage in pricing negotiations. A customer demonstrably running multiple models negotiates from strength.
- Innovation lag: when a better model launches from a competing provider, a locked-in customer faces a 3-6 month migration project before they can use it. A multi-model customer redirects traffic in hours.
- Talent retention: engineers want to work with the best tools. Locking into a single model provider signals architectural stagnation — the opposite of what retains strong engineering talent.
Implementation on Amazon Bedrock: The Multi-Model Architecture
Architecture Overview
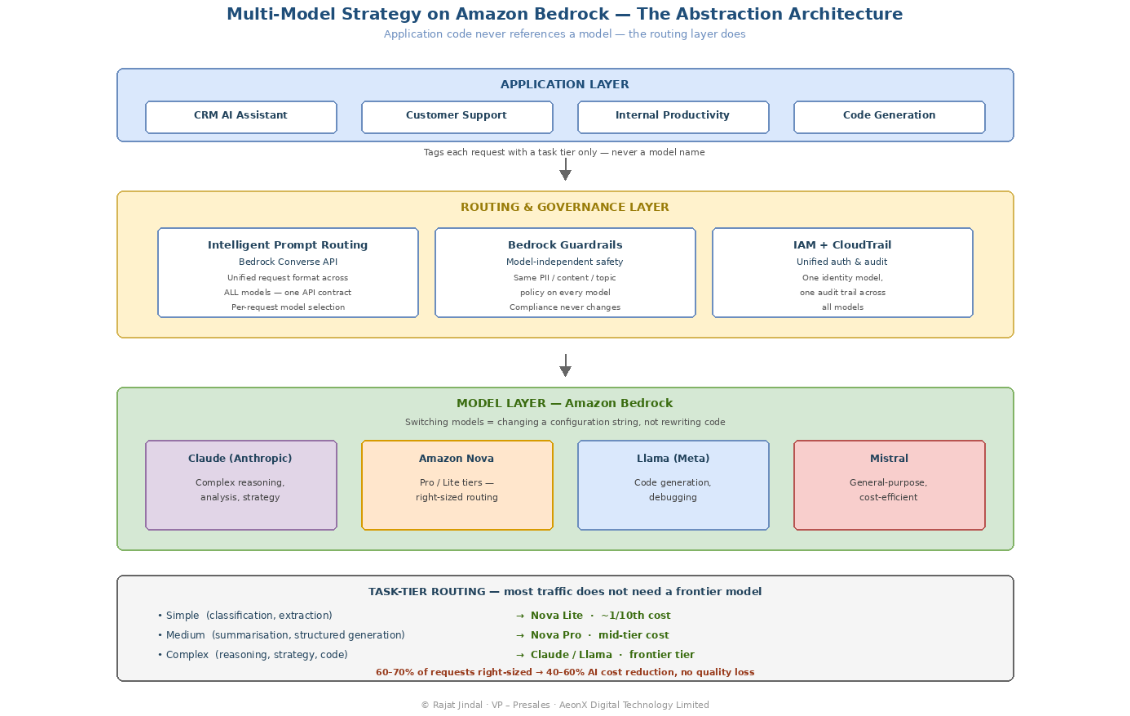
Building Block 1: Model Routing by Task Type
The simplest multi-model pattern routes requests based on declared task type. Your application tags each request with its complexity tier, and the routing layer selects the appropriate model.
import boto3
import json
bedrock_runtime = boto3.client('bedrock-runtime', region_name='ap-south-1')
# Model routing configuration — change here, not in application code
MODEL_ROUTING = {
"simple": "amazon.nova-lite-v1:0", # Classification, extraction, simple Q&A
"medium": "amazon.nova-pro-v1:0", # Summarisation, structured generation
"complex": "anthropic.claude-3-5-sonnet-20241022-v2:0", # Reasoning, analysis, strategy
"code": "meta.llama3-1-70b-instruct-v1:0" # Code generation, debugging
}
def invoke_model(prompt: str, task_tier: str, max_tokens: int = 1024):
"""
Route AI requests to the appropriate model based on task complexity.
Application code never references a specific model — only a task tier.
"""
model_id = MODEL_ROUTING.get(task_tier, MODEL_ROUTING["medium"])
# Unified request format — works across all Bedrock models
response = bedrock_runtime.invoke_model(
modelId=model_id,
contentType="application/json",
accept="application/json",
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31" if "anthropic" in model_id else None,
"messages": [{"role": "user", "content": prompt}],
"max_tokens": max_tokens
})
)
return json.loads(response['body'].read())
# Example usage — application code is model-agnostic
result = invoke_model(
prompt="Categorise this support ticket: 'Cannot login to portal'",
task_tier="simple" # Routes to Nova Lite — fast, cheap, sufficient
)
result = invoke_model(
prompt="Analyse the architectural trade-offs between ECS and EKS for this workload...",
task_tier="complex" # Routes to Claude 3.5 Sonnet — maximum reasoning quality
)The critical design decision: when you discover a better model for a task tier — or when pricing changes make a different model more attractive — you update the MODEL_ROUTING dictionary. Zero application code changes. Zero redeployment of downstream services. This is the architectural property that eliminates lock-in.
Building Block 2: Intelligent Prompt Routing (Preview)
Amazon Bedrock Intelligent Prompt Routing takes this further — it automatically routes prompts to different models within a model family based on the complexity of each individual prompt, without requiring you to manually classify task tiers.
Announced at re:Invent 2024 and available in preview, Intelligent Prompt Routing dynamically predicts the response quality of each model for a given request and routes accordingly. Simple prompts go to smaller, faster, cheaper models. Complex prompts go to larger, more capable models. The routing decision happens per-request, in real-time, with no application code changes.
The business impact: AWS states this can reduce costs by up to 30% without compromising accuracy — because the majority of prompts in any production workload do not require frontier-model reasoning.
Building Block 3: Guardrails Across All Models
A critical governance requirement for multi-model architectures: your safety controls must apply uniformly regardless of which model processes the request. Amazon Bedrock Guardrails provides this — a single guardrail configuration enforced across every model in your routing tier.
{
"name": "enterprise-ai-guardrail",
"description": "Applied to ALL models regardless of routing decision",
"contentPolicyConfig": {
"filtersConfig": [
{"type": "HATE", "inputStrength": "HIGH", "outputStrength": "HIGH"},
{"type": "VIOLENCE", "inputStrength": "HIGH", "outputStrength": "HIGH"},
{"type": "SEXUAL", "inputStrength": "HIGH", "outputStrength": "HIGH"},
{"type": "MISCONDUCT", "inputStrength": "HIGH", "outputStrength": "HIGH"}
]
},
"sensitiveInformationPolicyConfig": {
"piiEntitiesConfig": [
{"type": "EMAIL", "action": "ANONYMIZE"},
{"type": "PHONE", "action": "ANONYMIZE"},
{"type": "CREDIT_DEBIT_CARD_NUMBER", "action": "BLOCK"}
]
},
"topicPolicyConfig": {
"topicsConfig": [
{
"name": "competitor-discussion",
"definition": "Questions about or comparisons with specific competitor products",
"type": "DENY"
}
]
}
}This guardrail applies identically whether the request is routed to Claude, Nova, Llama, or Mistral. The governance layer is model-independent — which means your compliance posture does not change when you change models. For regulated industries, this property is non-negotiable: you cannot have different safety guarantees depending on which model happens to process a request.
Building Block 4: Cross-Region Inference for Resilience
A multi-model architecture inherently provides resilience that a single-model architecture cannot. But Amazon Bedrock adds another layer: cross-region inference automatically distributes traffic across regions during peak demand, providing up to 2x throughput without any application changes.
For enterprises with data residency requirements, cross-region inference can be configured with geographic boundaries — ensuring that inference processing stays within approved jurisdictions while still benefiting from multi-region resilience.
A Presales Perspective: How to Position Multi-Model Strategy in Customer Conversations
The Conversation Pattern That Works
In my experience, the multi-model conversation resonates most strongly when framed not as a technical architecture decision, but as a procurement and negotiation strategy.
Step 1 — Surface the hidden lock-in
Most enterprises do not realise they are locked in until they try to move. The question I ask: “If your primary AI model provider raised prices by 50% tomorrow, how long would it take you to switch to an alternative?” If the answer is “months” or “we’d have to rewrite our application,” they are locked in. That recognition is the opening.
Step 2 — Show the economics
Walk through the task-tier analysis: what percentage of their AI traffic actually requires frontier-model reasoning? In every enterprise I have analysed, the answer is 20-40%. The remaining 60-80% is classification, extraction, simple summarisation — tasks where a model at 1/10th the price delivers equivalent quality. That gap is their multi-model savings opportunity.
Step 3 — Demonstrate the Bedrock advantage
The reason Amazon Bedrock wins this conversation is simple: it is the only platform that provides Claude, Nova, Llama, and Mistral through a single API, single governance layer, and single billing relationship. The alternative — integrating directly with each provider’s API — creates the exact multi-vendor management complexity that enterprises are trying to avoid.
The Objections You Will Hear
“We’re already standardised on [Provider X]”
Response: “That’s fine for today’s workload. But which model will be best for your workload in 12 months? If it’s a different provider, how much does switching cost? Bedrock lets you keep using [Provider X] today while maintaining the architectural option to switch tomorrow — at zero additional cost.”
“Multi-model adds complexity”
Response: “Direct multi-provider integration adds complexity. A platform that abstracts model selection behind a unified API removes complexity. You write to one API. The routing is configuration, not code.”
“Our developers prefer [Model Y]”
Response: “Developer preference is valid for development and experimentation. Production model selection should be based on evaluation data — cost, quality, latency — not preference. Bedrock Model Evaluation gives you that data. Often, the model developers prefer for interactive use is not the most cost-effective for production batch workloads.”
The Model Lock-In Test: Five Questions for Technology Leaders
Ask your team these five questions. If more than two answers are “yes,” you have a lock-in problem:
- Does your application code directly reference a specific model provider’s API? (Not Bedrock’s unified API — the provider’s own SDK/endpoint)
- Would changing AI models require code changes in more than one service?
- Do you have a single AI vendor whose pricing increase would directly impact your P&L with no short-term alternative?
- Is your AI cost per transaction increasing quarter-over-quarter despite traffic being stable? (You are paying frontier prices for non-frontier tasks)
- Has your team evaluated an alternative model in the last 90 days? (If no, you have lock-in by inertia, not by choice)
If your score is 3+ “yes” answers, the multi-model conversation is urgent — not because your current model is bad, but because your current architecture is fragile.
Why This Matters Now: The 12-Month Forecast
Three developments will make multi-model strategy mandatory — not optional — within the next 12 months:
- Model specialisation is accelerating — general-purpose models are being joined by task-specific models (code, reasoning, vision, structured data) that dramatically outperform generalists on their target task. A single-model strategy cannot access these specialists.
- Pricing competition will intensify — as more providers reach production quality, pricing will compress further. Enterprises with multi-model flexibility will capture these savings automatically. Locked-in enterprises will watch from the sidelines.
- Regulatory requirements will fragment model choice — emerging AI governance frameworks in the EU, India, and other jurisdictions will create scenarios where specific data types must be processed by models meeting specific residency or certification requirements. A single-model architecture cannot accommodate this without parallel infrastructure.
The enterprises that build multi-model architecture now will have 12 months of operational experience, evaluation data, and cost optimisation when these forces arrive. The enterprises that wait will face a combined migration-and-compliance project under time pressure. Which position would you rather be in?
Lessons for Technology Leaders
- “Which model should we use?” is the wrong first question — The right question is “How do we build an architecture that lets us use the best model for each task and change models without re-engineering?” Answer that first, and the model selection question becomes a configuration decision, not an architecture decision.
- Multi-model is a cost strategy, not just a risk strategy — The immediate savings from right-sizing models to tasks (40-60% cost reduction on AI workloads) pays for the architectural investment in months, not years. This is not theoretical — it is arithmetic.
- Amazon Bedrock is not an AI service — it is an AI platform strategy — The value of Bedrock is not any single model. It is the unified API, governance, and billing that makes model switching a configuration change. That architectural property is worth more than any individual model capability.
- Model evaluation should be a quarterly practice, not a one-time decision — The model landscape changes every quarter. If you are not re-evaluating, you are overpaying — either in cost (using an expensive model where a cheaper one suffices) or in quality (using last quarter’s best when this quarter’s best is available).
- The CTO who says “we’re a Claude shop” or “we’re a Llama shop” is making a procurement statement, not an architecture statement — In 12 months, that statement will be as outdated as “we’re an Oracle shop” is today. Build for flexibility.
About the Author
Rajat Jindal is VP – Presales at AeonX Digital Technology Limited, where he architects winning cloud strategies for enterprise customers and translates modernization into measurable business value. He is a strong advocate of AWS, committed to sharing thought leadership that helps technology leaders make faster, better-informed decisions.